Why does it matter how models learn?
The rapid advance of large language models has raised a fundamental question that is surprisingly difficult to answer: why does a model behave the way it does? Modern transformers are trained on vast datasets, and they develop capabilities whose origins are poorly understood. This matters for AI reliability and safety. If we cannot explain where a capability comes from, we cannot reliably predict when it will appear, how it will behave out of distribution, or whether it might emerge from training data in unexpected ways.
Rather than studying billion-parameter models that are expensive to train and almost impossible to interpret, we study the smallest model that still exhibits the behaviour we care about. This allows us to control every variable, including the training data, the model architecture, and the training procedure, and we vary one thing at a time.
The importance of the training dataset
It seems natural to us that to understand how models acquire capabilities from the training data, we must have access to and directly analyze the training data themselves. This involves examining the specific patterns, distributions, and information structures within the input corpus to determine how they drive potentially emergent capabilities. This data-centric perspective complements the circuit-level analyses prevalent in mechanistic interpretability. By analyzing the input data, we hope to identify the precise signals that enable the model to acquire a given capability. In our experiment-driven approach, we are then also able to modify the input data in a well-defined way, train a new model, and compare the outputs and performance metrics of the modified and unmodified models.
Token repetition as a simple capability
We define a capability as a specific operation on input tokens that produces a well-defined category of output tokens. Transformers perform many such operations, from simple ones, such as repeating a word, to complex ones, such as answering a factual question. We focus on a simple non-trivial capability, the repetition of a sequence of tokens.
Suppose the model sees the token sequence ... [A] [B] ... [A] and is asked to predict the next token. A model with the capability of modelling repetition will predict token [B] appearing next with higher probability than other tokens. A model without that capability will on average, not predict token [B] with a higher probability than other tokens.
This capability is known to be mediated by induction heads and via a circuit that forms in two-layer transformers and allows them to complete repeated sequences by looking up prior context. The existence of induction heads has been demonstrated in many previous works. We aim to investigate the following questions:
- What property of the training data causes them to form?
- Once they form, is the resulting capability memorisation or genuine generalisation?
Our setup
Model: We use a standard transformer architecture with 2 layers, 8 attention heads, and a . The MLP layers use a GELU activation with dimension 2048. The model has approximately 25 million parameters. Training uses the AdamW optimiser with a cosine learning rate schedule, a peak learning rate of , and a batch size of .
Training data: We train on the Pile dataset, an 800 GB corpus of English text. We tokenize the dataset with the Llama 2 tokeniser, giving a vocabulary of 32,000 tokens. We optimised the baseline training setup to reliably generate induction heads after training for about 70 million tokens, and we use 200 million tokens per training run (takes about 1 hour on an A6000 GPU). We ran a variety of tests to verify our approach produces sufficiently strong induction performance to address our research questions while keeping compute manageable. All models are trained from scratch with random weight initialisations.
Baseline performance
The starting point for our research is simply verifying that a two-layer transformer trained on the Pile does indeed develop induction heads and acquire the repetition capability.
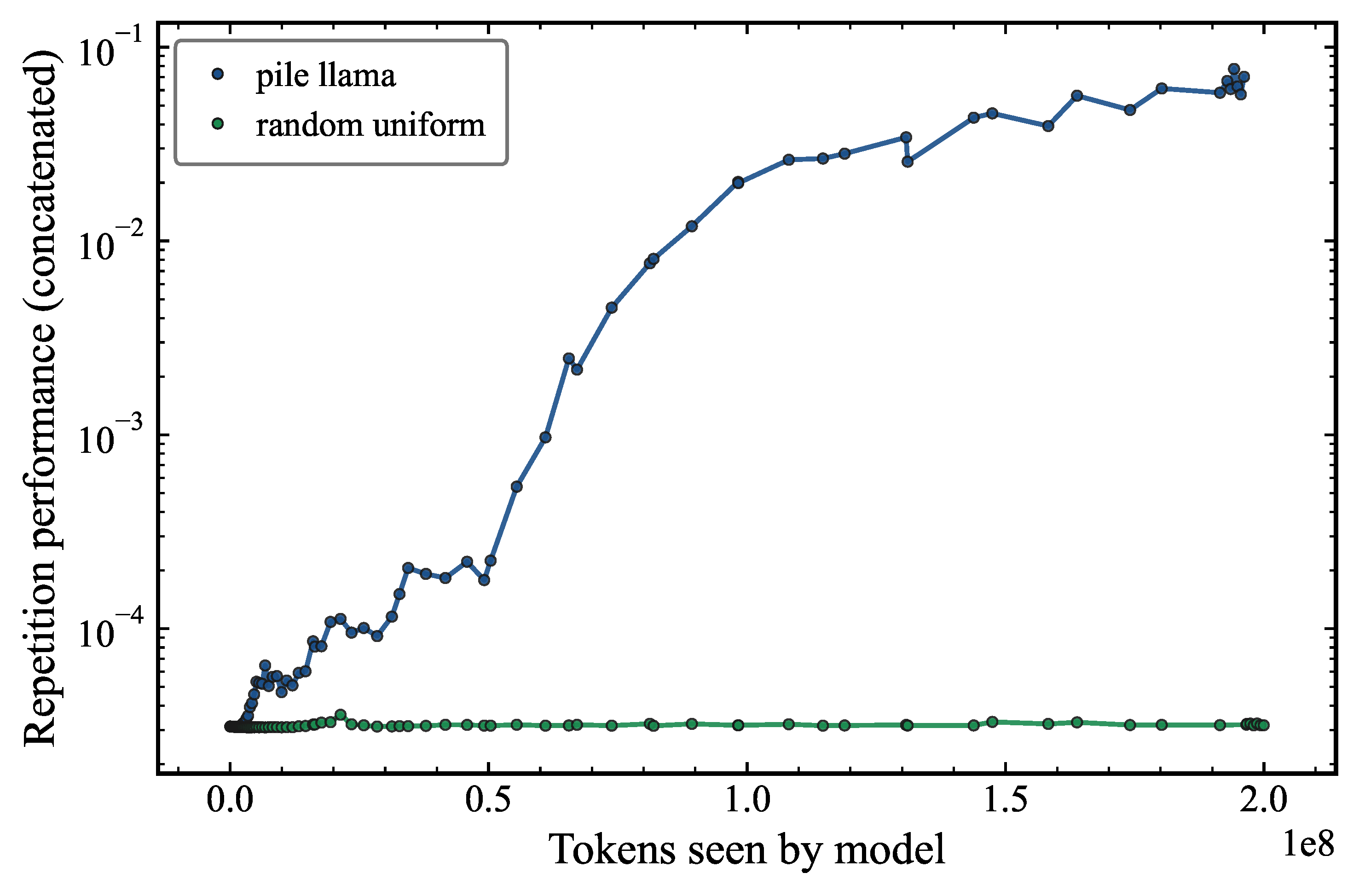
As shown in Figure 1, we see that the model is able to repeat a sequence of 8 random tokens well above the expected random guess level of 3.2 × 10−5. By design, our setup allows the model acquires the capability quite early in the training process.
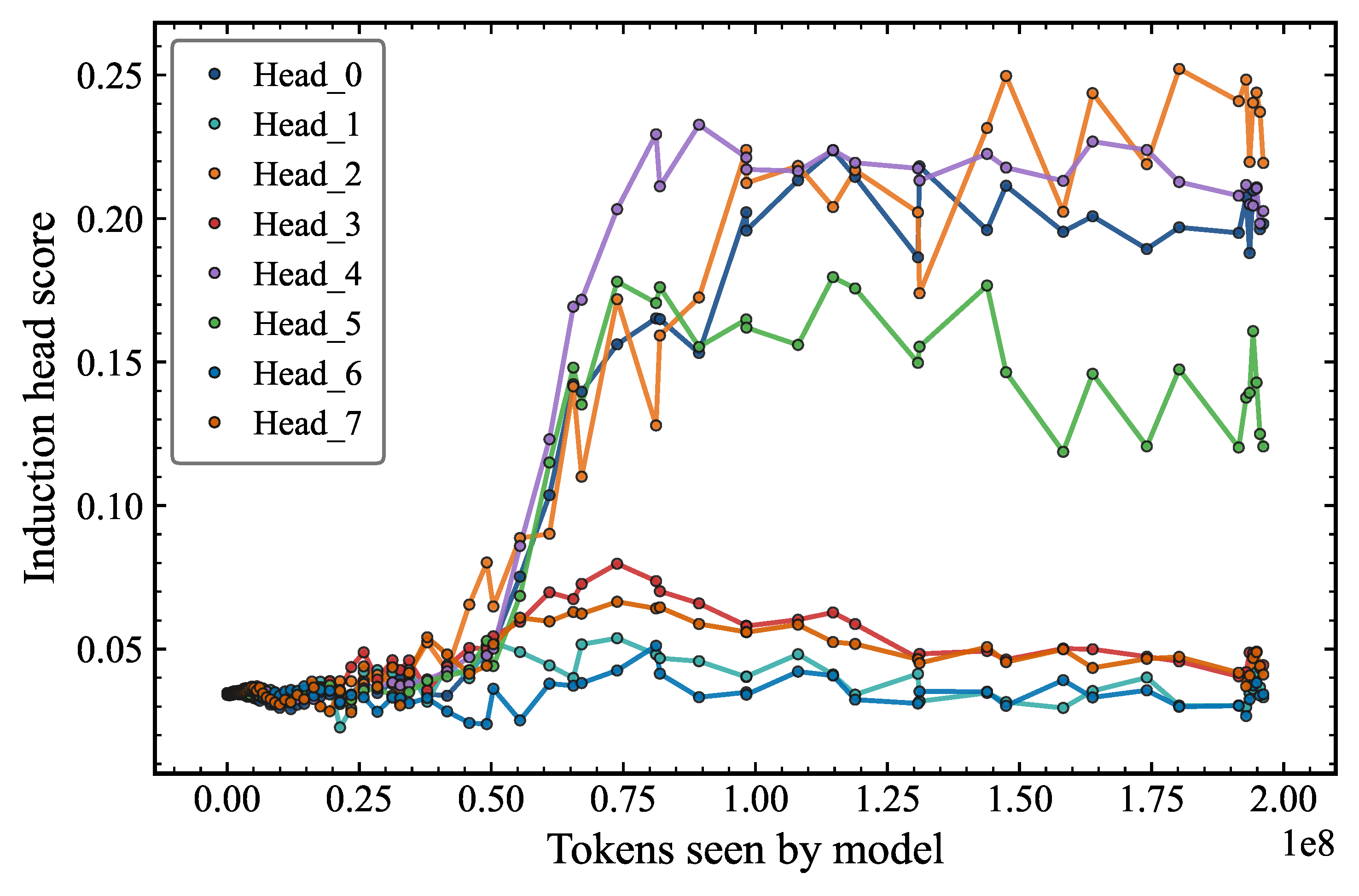
Before 50 million, we find that the model memorizes bigrams and trigrams. This early-phase memorization is consistent with findings in the language modeling literature suggesting that models first acquire low-order statistical associations before developing more structured in-context mechanisms1. Even at this stage, the repetition performance achieves around 20x the baseline value from random sampling. Then, after around 50 million tokens have been seen by the model, a rapid evolution in the repetition performance is seen when the “induction” heads form more prominently (Figure 2). This behavior sets the stage for our scientific research into the fundamental question of how transformers acquire capabilities. While a mechanistic description of the induction head behavior has been presented and discussed in the literature23, in our view this still does not fully explain what causes the model to acquire the repetition capability in the first place. In particular, the role of the training data distribution and the effects of different generators have received comparatively little attention, and constitutes the central focus of this work.
Footnotes
-
Chan et al. (2022). Data Distributional Properties Drive Emergent In-Context Learning in Transformers. NeurIPS. ↩
-
Olsson et al. (2022). In-context Learning and Induction Heads. Transformer Circuits Thread. ↩
-
Elhage et al. (2021). A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread. ↩