Before training the toy transformers, we set out to directly characterise the repetition structure of our training data. The results were striking enough that they deserve a post of their own.
We used the Pile and Wikitext datasets with the Llama 2 and GPT-NeoX tokenizers. The use of two independent datasets and two tokenizers serves as a cross-validation of the generality of our findings, allowing us to distinguish properties intrinsic to natural language from those that are artifacts of a particular corpus or tokenization scheme.
Definition of repeated sequences
We define a repeated sequence as a sequence that appears multiple times in the dataset, e.g. a sequence of length 2 appears as ... AB ... AB ..., for any two tokens A and B, and ...ABC...ABC... for any tokens A, B, and C for a sequence length of 3. We then also define the repetition fraction as the fraction of tokens in the dataset that appear as the second B in ... AB ... AB ..., such that an induction mechanism could reliably predict the second B. Under this definition, a sequence of e.g. ABABCDCDEFEF, and so on, would have a repetition fraction of 0.25. For a sequence of ABABABABABAB...., the repetition fraction tends towards 1 as every token except for the first 3 are defined as "repeated tokens". We also define the repetition fraction as a function of sequence length such that for a sequence length of 3, the repeated token is the final token in a repeated sequence of ABCABC. Packing concatenated sequences of length 3 would produce a repetition fraction of 0.167.
Repetition fractions
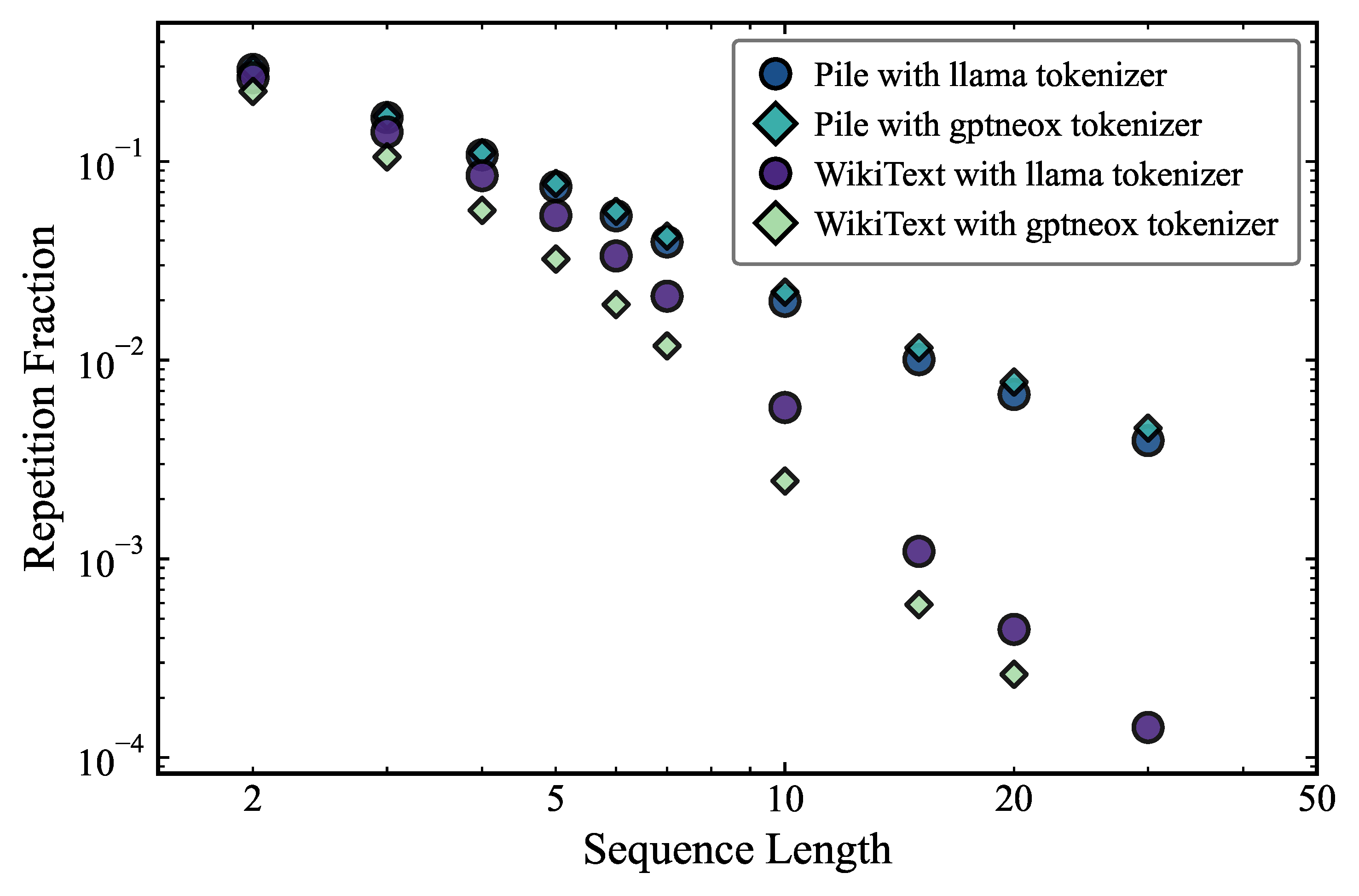
Figure 1 shows the fraction of repeated sequences of a given length for different natural language datasets.
The first striking result is that for the Pile dataset with the Llama 2 tokenizer, we find a repetition fraction 29.4% for a sequence length of 2, decreasing to 3.9% for sequence length 7 and 0.4% for sequence length 30. This demonstrates that both the Pile and Wikitext datasets contain a substantial amount of repeated sequences and that the fraction of repeated sequences decreases steeply with sequence length. This is independent of the tokenizer used, with the tokenizer changing only slightly the amount of repetitions for a given dataset and sequence length. This provides further evidence that this is a property of the data itself rather than a property of the tokenizer. The steep decay of repetition fraction with sequence length is broadly consistent with a generative process in which tokens are drawn with short-range correlations, such that the probability of an exact -gram recurrence decreases combinatorially with . This is a key finding that supports our hypothesis that the repetition capability of transformers is strongly dependent on the training data. With that in mind, from here on we focus on the Pile with Llama 2 tokenizer dataset.
Different datasets have slightly different repetition fractions, with Pile having slightly more repetitions than Wikitext.
An additional key finding is the overall proportion of tokens located in repeated sequences of any length. We observed that the Pile + Llama 2 dataset contains approximately 55% of its tokens in such repeated sequences. This relatively high fraction underscores the degree to which repetition is not a peripheral feature of language data but rather a dominant structural property.
Token and bigram frequency distributions
We next focus on the token frequency distribution of the Pile + Llama 2 dataset. We compute the token frequencies for tokens that are part of repeated sequences and those that are not part of repeated sequences. The results are shown in Figure 2, sorted in descending order of rank (i.e. most frequent). We see that tokens in repeated sequences have a higher frequency than tokens not in repeated sequences. In particular for the most frequent tokens with token rank less than 20, sequence tokens are predominantly dominant. This is consistent with the idea that repeated sequences are more common in the training data.
We also see that the shape of the token frequency distribution is similar for both groups, with a long tail of low-frequency tokens. This is expected for a natural language dataset, following a power law distribution similar to Zipf's law. The preservation of this power-law shape across both sequence and non-sequence tokens suggests that the repetition structure of the Pile is not associated with a qualitatively different token vocabulary, but rather with a systematic elevation in the frequency of an already-dominant subset of tokens.
Figure 3 shows the bigram frequency distribution for bigrams that are part of repeated sequences and those that are not part of repeated sequences. We see that bigrams in repeated sequences have a higher frequency than bigrams not in repeated sequences. Again, this is consistent with the idea that repeated sequences are more common in the training data. For the most frequent bigrams (rank below 1000), the bigrams in repeated sequences are dominant. This again illustrates the amount of repetition present in natural language data, which we posit to be crucial for acquiring the repetition capability. The dominance of high-frequency bigrams in repeated sequences further supports the hypothesis that repetition frequency and reliability jointly control the formation of induction heads, since high-rank bigrams will be encountered most often during training.
Offset distributions and repetitions per row
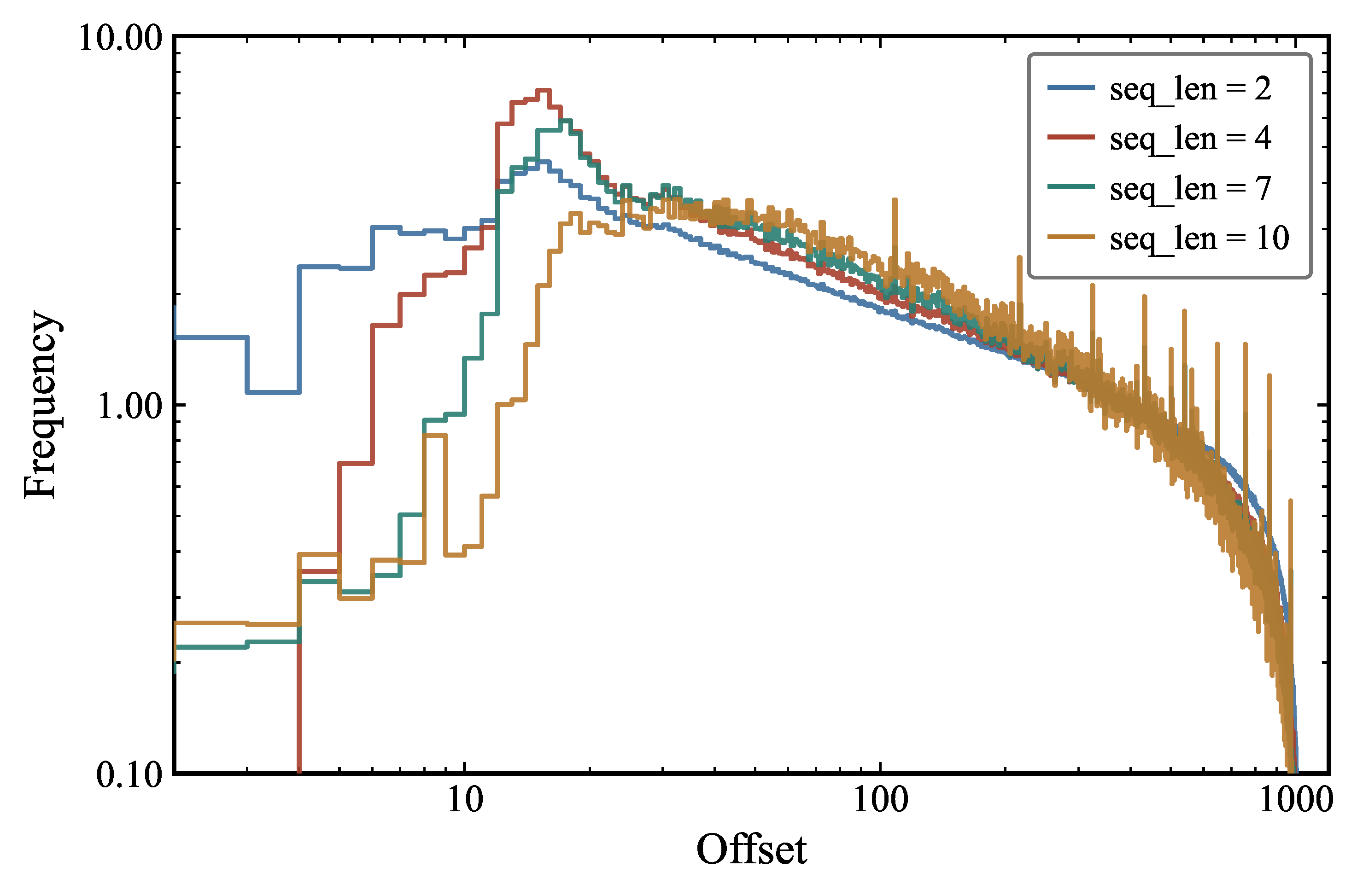
Figure 4 shows the empirical distribution of offsets for repeated sequences of different lengths in the Pile + Llama 2 dataset. Offset is defined as the number of tokens separating the end of one occurrence from the start of the next. Across all sequence lengths the distributions exhibit heavy-tailed behavior, with frequencies decaying approximately as a power law for large offsets and then truncated at the end. Shorter repeats (e.g., ) distributions are shallower and retain relatively higher frequency at large offsets. Conversely, longer repeats ( and 10) are concentrated toward smaller offsets, implying that longer exact repetitions are more localized. All curves attain a maximum at modest offsets (– tokens) and thereafter decline monotonically; the tail shows increasing stochasticity due to sparse sampling for longer sequences. The heavy-tailed offset distribution is reminiscent of long-range correlations observed in natural language at the character and word level, and suggests that the repetition signal available to a transformer spans a wide range of context window positions.
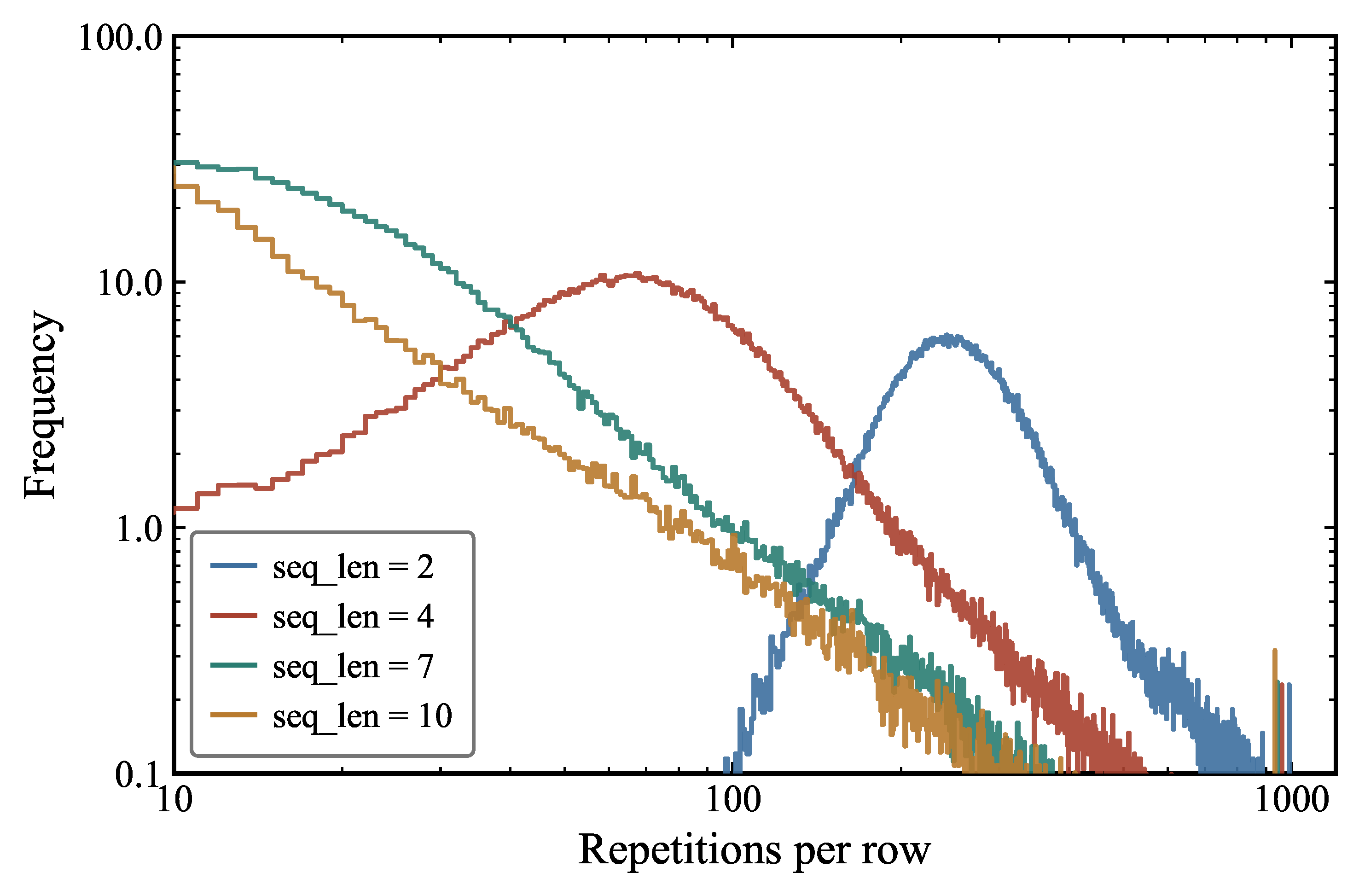
It is also interesting to analyze the distribution of repetitions per row (Figure 5). Each sequence length yields a distinct unimodal profile whose peak shifts systematically with . Specifically, peaks at offsets of roughly 200–300 tokens, whereas peaks near 10–20 tokens. We find that longer sequences tend to repeat over shorter spans, while shorter sequences repeat over broader contexts.
Together, Figures 4 and 5 demonstrate that repetition statistics in the dataset are simultaneously heavy-tailed and strongly modulated by sequence length, with longer sequences exhibiting more localized and tightly constrained recurrence patterns. We conclude that these patterns reflect fundamental properties of token-level repetitions in large language-model training datasets. These findings motivate our subsequent controlled experiments, in which we surgically modify the repetition structure of the training data to isolate its causal contribution to model behavior.