Having established the ubiquity of repetition in language data, we now investigate whether natural language is required for the acquisition of repetition capabilities by transformers.
Reversing tokens in the Pile dataset and mixing rows with the original dataset
We reverse the order of all tokens in the Pile dataset, then mix the original Pile dataset with rows of the reversed version of the dataset in various proportions, and train a new model using the modified dataset. This allows us to systematically vary the amount of "naturalness" in the training data and observe how this affects the model's ability to repeat sequences. Crucially, token reversal preserves the marginal token frequency distribution and the total number of repeated bigrams and trigrams, while destroying the higher-order syntactic and semantic structure of the language. It therefore allows us to decouple the contribution of low-order statistical regularities from that of linguistic structure.
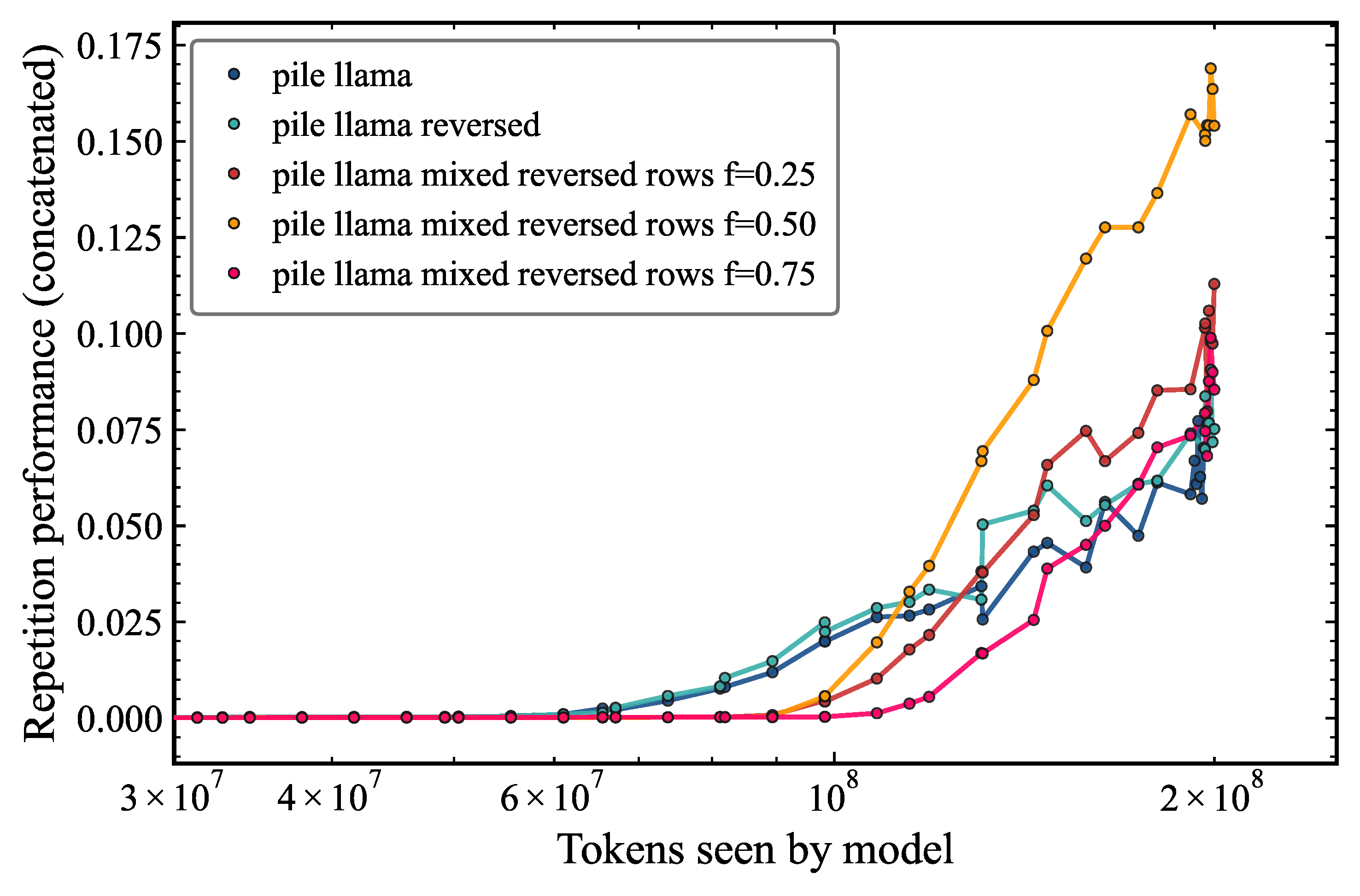
Figure 1 shows the evolution of repetition performance as a function of the number of tokens seen by the model, plotted on a log-linear scale across the five experimental conditions derived from the pile_llama dataset.
The first striking result that we find is that the reversed pile_llama model learns repetition following a similar curve as the original pile_llama model. This suggests that the model is able to learn to repeat even when the training data is completely unnatural. This finding implies that high-level linguistic structure such as syntax, semantics, and discourse coherence is not a prerequisite for induction head formation, and that the low-order token repetition statistics are sufficient. Secondly and perhaps even more strikingly, we see that the model trained on a mixed dataset with 50% reversed tokens and 50% original tokens (orange) actually has a higher repetition performance than the model trained on the original dataset. One possible interpretation is that the mixing of forward and reversed sequences increases the effective diversity of bigram contexts encountered during training, providing a richer learning signal for the induction mechanism. Alternatively, the reversed rows may act as a form of data augmentation that reduces overfitting to specific token sequences, thereby improving the performance of the repetition capability.
Regarding the behavior during training, we find that all experimental conditions exhibit a consistent near-zero repetition performance up to approximately 60m tokens, after which a monotonic increase is observed, showing that repetition behavior emerges only after sufficient training exposure. The consistent onset threshold across all conditions is notable and suggests that the model requires a fixed amount of training exposure before any repetition mechanism can begin to consolidate, regardless of the specific data composition. This is reminiscent of the "phase-transition" behavior described by Olsson et al. (2022)1, and may suggest a lower bound on the training budget required for induction head formation, given our choice of architecture and vocab size.
The baseline pile_llama (dark blue) and reversed pile_llama (teal) conditions follow closely aligned trajectories throughout training, converging to repetition values of approximately 0.055–0.065 at 200m tokens, indicating that naive token-order reversal has minimal effect on repetition dynamics. This near-identical performance between the original and fully reversed models constitutes strong evidence that the repetition capability is driven primarily by the statistics of the repetition structure of the data rather than by any directional or semantic property of natural language.
Among the mixed reversed-row conditions, the model with 50% of reversed rows (orange) displays markedly elevated repetition performance relative to all other conditions, rising steeply from tokens onward and reaching peak values of at the end of training. This is nearly three times that of the baseline pile_llama model. In contrast, the model with 25% of reversed rows (dark red) follows a trajectory closely mirroring the baseline, suggesting that a low mixing fraction of reversed rows is insufficient to substantially alter repetition behavior. Notably, the model with 75% of reversed rows (magenta) exhibits a pronounced delayed onset of repetition growth, remaining suppressed until 150m tokens before rising sharply, ultimately approaching baseline-level values. The non-monotonic dependence on mixing fraction, with the 50% mixture outperforming both extremes, suggests an interesting interaction between the two data sources. This warrants further investigation.
Footnotes
-
Olsson et al. (2022). In-context Learning and Induction Heads. Transformer Circuits Thread. ↩