We now want to investigate whether the repetition behavior is regulated by the tokens themselves or by the structure of the sequences. The following experiments allow us to assess the independent and joint contributions of the sequence and non-sequence token populations.
Modifying sequence tokens in the Pile dataset using different generators
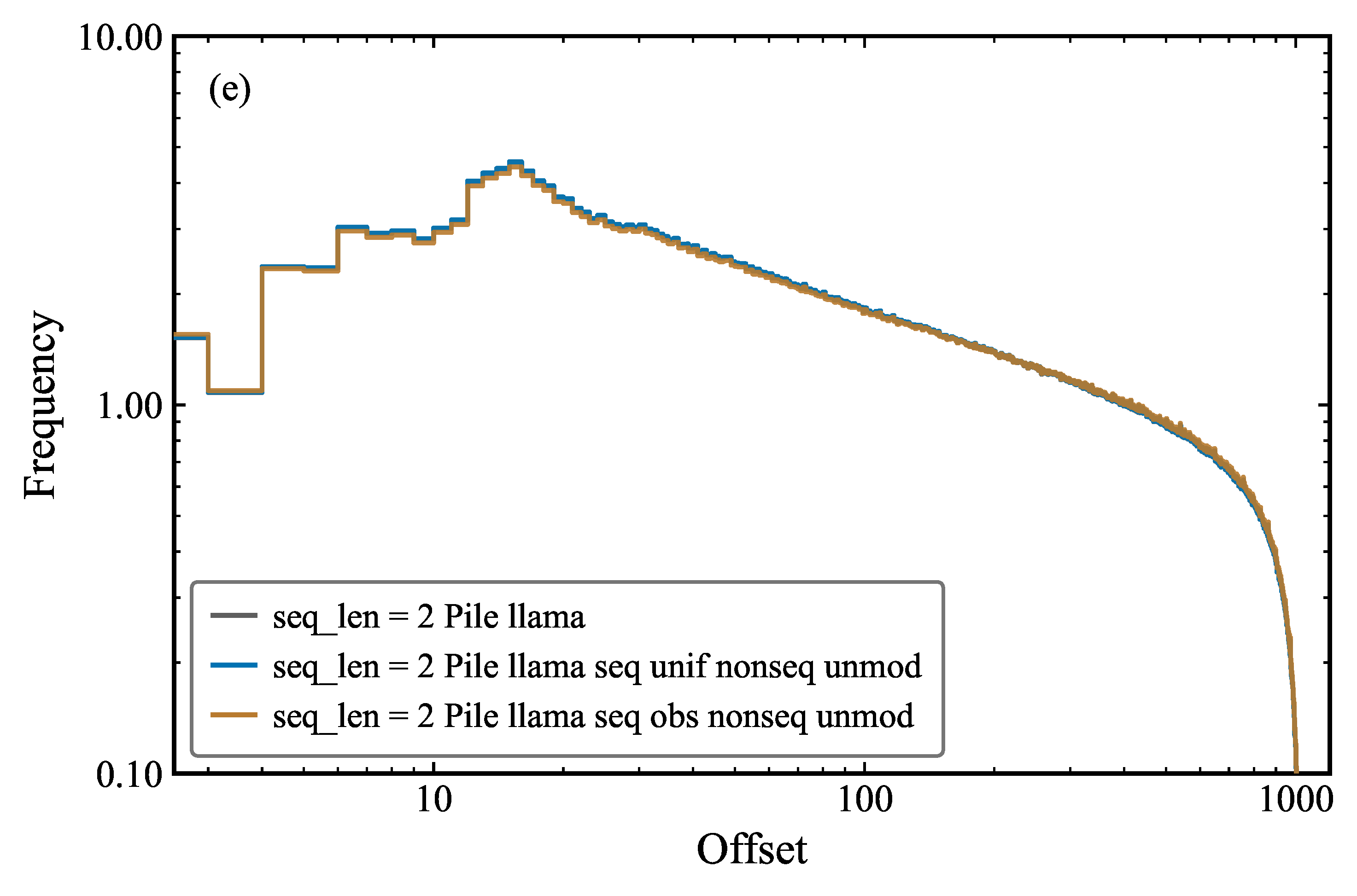
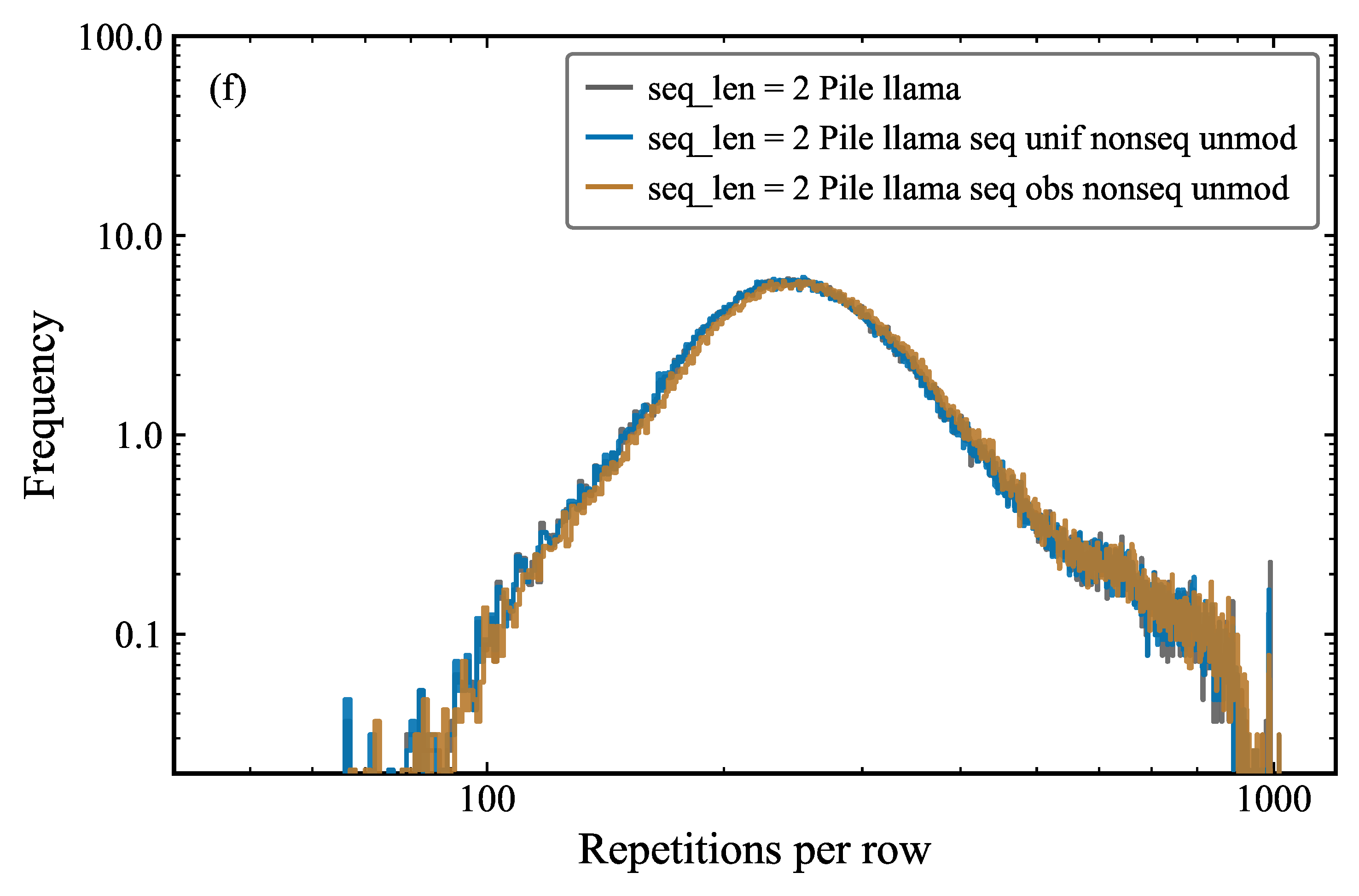
We modify the sequence tokens in the Pile dataset by replacing them with random tokens from different generator functions, while keeping the sequence structure intact. By that we mean that we keep the repetition offset, repetitions per row, repetitions per column, and other repetition metrics fixed in sequences (Figures 5 and 6).
The non-sequence tokens and non-sequence bigrams are also kept constant (Figures 2 and 4). This allows us to test whether the repetition behavior is dependent on the specific tokens or on the sequence structure. This experimental design constitutes a precise intervention. By varying the token identity while holding the repetition structure constant, we can isolate the contribution of the token frequency distribution from that of the repetition pattern itself.
When we modify the sequence tokens using a uniform random token generator, we observe that the token frequency distribution is flatter than the original pile_llama model, as expected (Figure 1). When we use the observed token frequency distribution, we observe that the token frequency distribution is closer to the original pile_llama model (Figure 1), with the differences being due to random sampling of sequence tokens becoming non-sequence tokens.
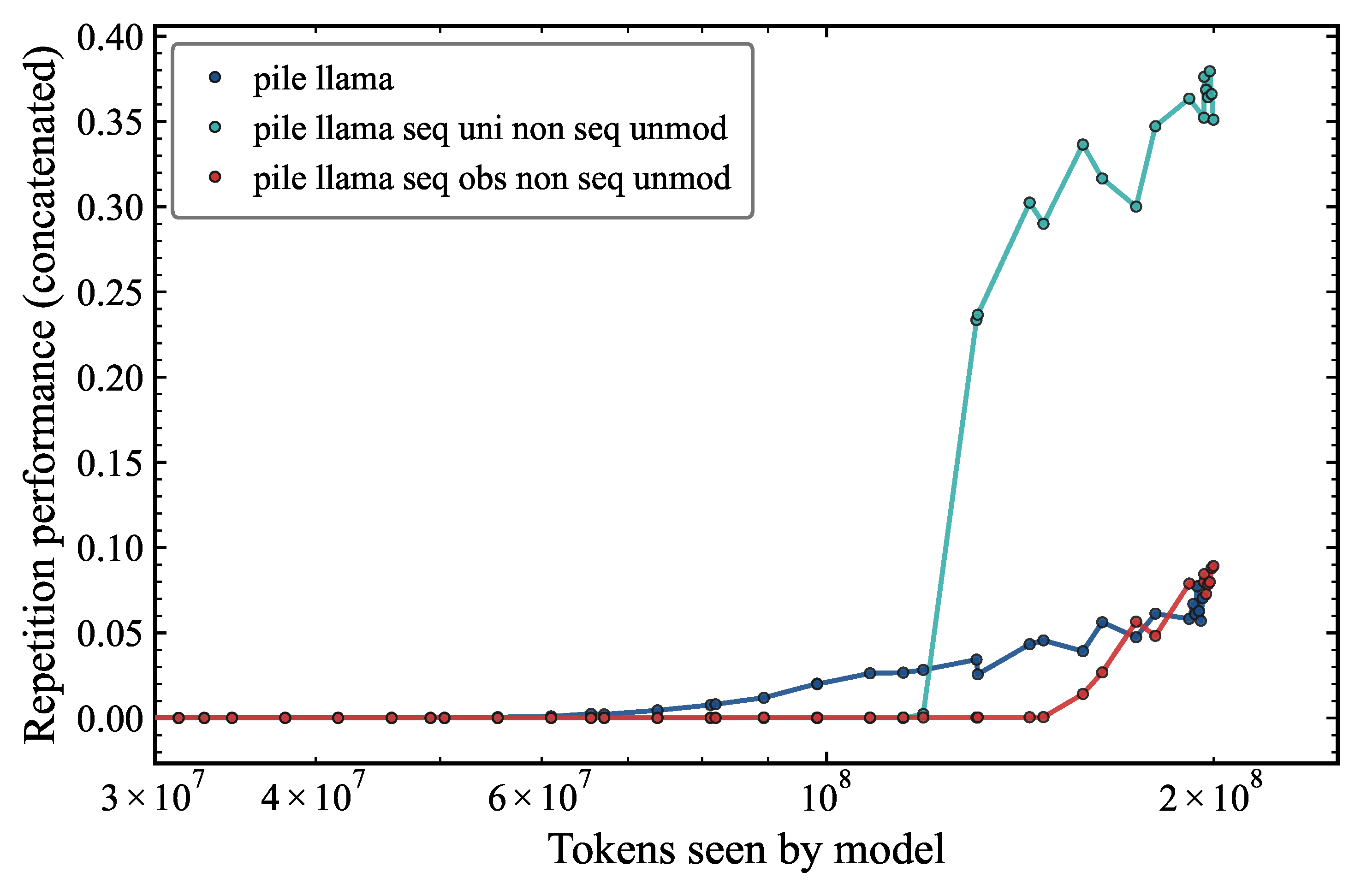
We see that the model with sequences randomly sampled from a uniform distribution and non-sequences unmodified (teal) has a much higher repetition performance than the baseline model, achieving 0.38 at the end of training vs 0.08 for the baseline model. This occurs despite the uniform-sequence model learning repetition much later in the training process. The model with sequences randomly sampled from the observed distribution and non-sequences unmodified (red) has an only slightly higher repetition performance than the baseline model. The dramatic improvement achieved by the uniform random sequence token model is at first counterintuitive, since one might expect that replacing natural language tokens with uniformly random ones would degrade performance. However, this result can be understood by noting that uniform tokens in the repeated sequences create a maximally discriminative repetition signal. Because each token in repetitions is equally likely, any repeated pattern stands out sharply against the background distribution of non-sequence tokens, which retain their natural frequency distribution. This contrast likely facilitates the attention mechanism's ability to identify and learn repeated patterns.
This experiment shows that the repetition performance is highly dependent on the token distribution in the sequences, and that the structure of the sequences alone (i.e. the repetition pattern) is not sufficient to explain the repetition performance. Our conclusion here is that token distribution in the sequences is also a key factor. More precisely, our results suggest that it is the contrast between the token distribution in repeated sequences and that in non-repeated tokens that drives performance, rather than either distribution in isolation. This has important implications for dataset curation, because artificially flattening the token distribution within repeated sequences may inadvertently enhance the model's repetition capability.
Modifying non-sequence tokens in the Pile dataset using different generators
We have established that the frequency distribution of tokens in sequences is a key factor in determining repetition performance. Now we want to explore whether the frequency distribution of non-sequence tokens also plays a role. We now modify the non-sequence tokens in the Pile dataset by replacing them with random tokens from different generators, while keeping the sequence tokens and repetition structure fixed. We use a uniform random token generator and what we call an observed random token generator, which samples from the observed frequency distribution of tokens in the original Pile dataset. This experiment is the natural complement to the previous one. While before we varied the sequence token distribution while fixing the non-sequence tokens, here we do the reverse.
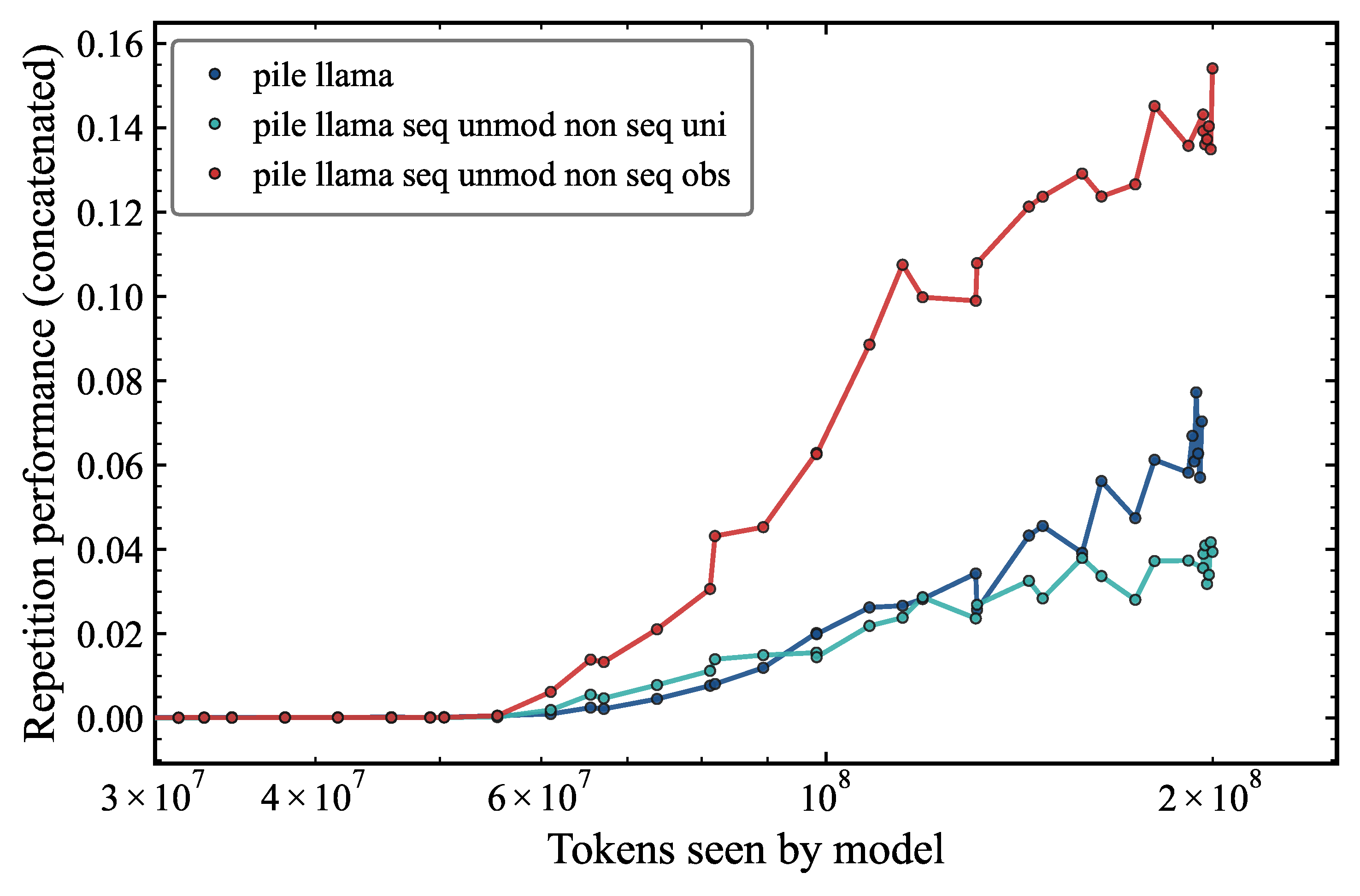
The behavior is markedly different from the sequence token modification experiment. In the non-sequence token modification experiment, we see that the modified models learn repetition much earlier than the baseline model. The repetition performance is much higher than the baseline model when non-sequence tokens are modified with a random observed token generator, achieving around 0.15. However the performance is substantially lower when non-sequence tokens are sampled from a uniform distribution (0.03). This is the opposite of what we saw in the sequence token modification experiment. The asymmetry between the uniform and observed non-sequence generators, with the observed generator leading to higher performance, further supports the interpretation that it is the relative contrast between sequence and non-sequence tokens that is the operative variable, rather than the absolute properties of either distribution.
Our somewhat surprising conclusion is that the non-sequence token distribution also has a strong effect on the repetition performance. Taken together with the sequence token modification experiment, these results establish that repetition performance is jointly determined by the token distributions of both sequence and non-sequence tokens, and specifically by the statistical contrast between them. This is a non-trivial finding that would have been challenging to anticipate from prior circuit-level analyses alone, and illustrates the value of the data-centric experimental approach adopted here.
Modifying both sequence and non-sequence tokens simultaneously
We have seen that both sequence and non-sequence tokens have a significant impact on the repetition performance. Now, we investigate what happens when we modify both sequence and non-sequence tokens at the same time. We do this by creating a model where both sequence and non-sequence tokens are sampled from a uniform distribution. This is a very extreme modification of the original Pile dataset. Under this condition, the contrast between sequence and non-sequence token distributions is eliminated by construction, since both are drawn from the same uniform generator. However, note that these datasets still have the exact same number of repeated sequences per row and distribution of repetition statistics in terms of the repetitions per sequence and offsets between sequences. One might expect that they still perform repetition, given the large fraction of repeated tokens in the dataset.
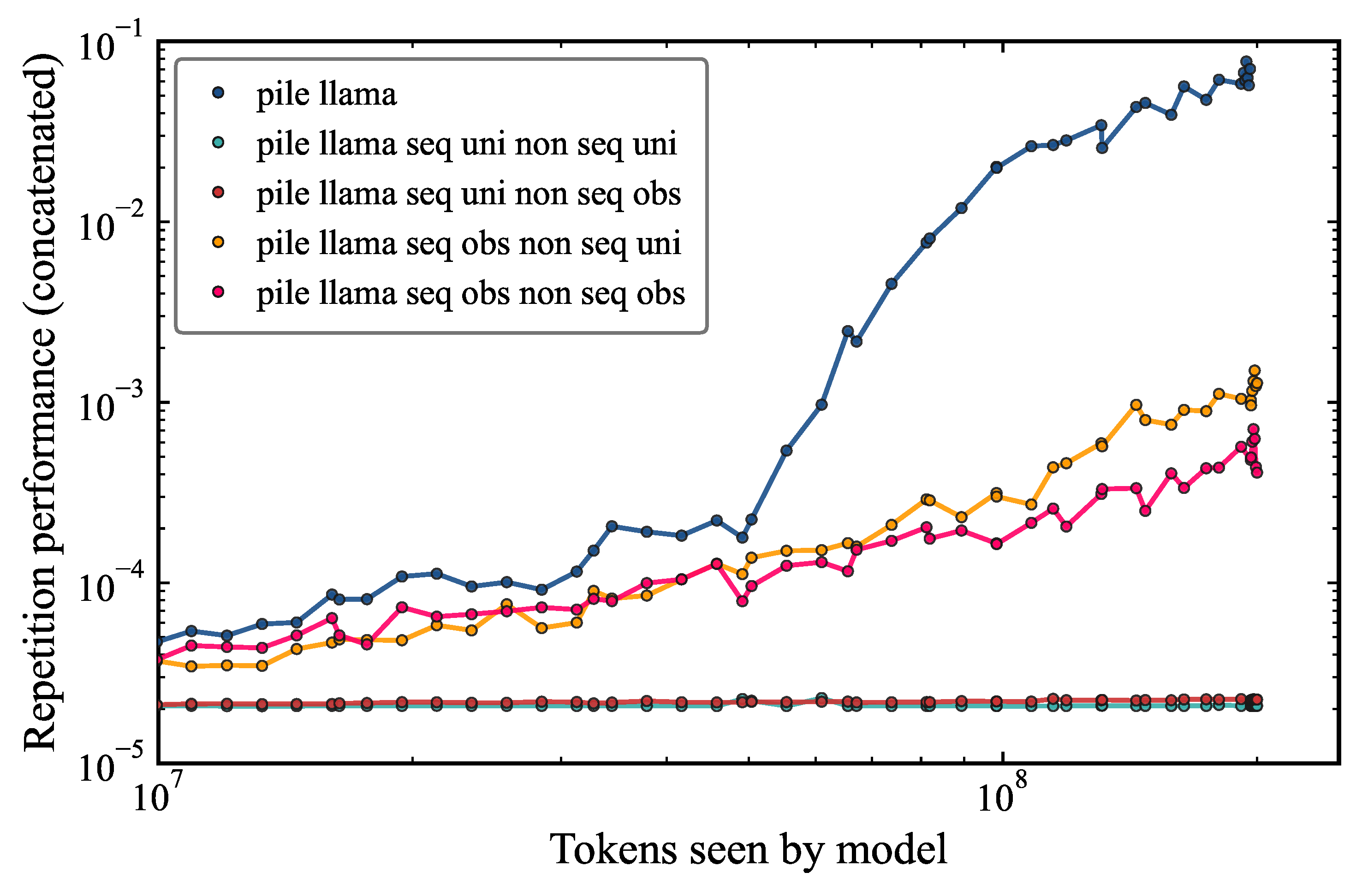
Figure 9 shows that the repetition performance is much lower than the baseline pile_llama model for these modified models. The models trained with random uniform sequence tokens are not able to learn to repeat sequences above the expected random guess level. This is regardless of the non-sequence token generator being the observed token distribution or uniform distribution. The models trained with sequence tokens from the observed distribution perform better than the models trained with uniform sequence tokens, but they do not develop induction heads still orders of magnitude below the baseline model. Tand their performance is 2 orders of magnitude below the baseline performance. When both populations are drawn from the same uniform distribution, no differential signal is available to the attention mechanism, and induction heads fail to form.
Subsequent results confirm that this is due to the fact that these models fail to develop previous token heads. Previous token heads appear to be a prerequisite to developing induction heads and without trigram information in the dataset, the model has little incentive to develop a previous token head, except to support an induction head. It's appears to be empirically quite difficult for gradient descent to produce a previous token head and an induction head simultaneously.
Appendix verifying the distributions of the semi-synthetic datasets