We have seen before that a model trained on the Pile dataset learns to repeat sequences because of the ubiquitous presence of repetitions with a given structure in the data. This brings the question of what would be the minimum amount of repetitions needed to learn the repetition pattern? In more technical terms, what would be the signal-to-noise ratio needed for the model to still learn repetition patterns? These questions are very relevant for AI safety, since the training data may contain data in trace quantities but that could still lead to undesirable capabilities being learned. This concern is related to the broader problem of data poisoning, where adversarially crafted examples present in small fractions of the training data can have outsized effects on model behavior. Our experiments address a complementary and arguably more worrying scenario in which even non-adversarial, naturally occurring patterns present at low frequencies may suffice to induce structured capabilities. We focus here on repeated sequences as these are easy to detect in the training data even in small amounts, and thus allow us to perform a detailed sensitivity analysis.
We answer these questions by doing two experiments: one adding random tokens to the Pile dataset on a token-by-token basis, with each token having a certain probability of being replaced by the random generator, and the other by replacing entire random rows of the Pile dataset by rows of random tokens.
Adding random tokens to the Pile dataset
We add random tokens to the Pile dataset in different fractions, from 30 to 90%, and then train a model on the modified dataset. The idea is that by adding random tokens on a token-by-token basis, we are increasing the noise within the context in the data. In this experiment the fraction of random tokens is the fraction of the total number of tokens in the dataset that are replaced by random tokens. This is done on a token-by-token basis, using as generator a uniform distribution. This element-wise corruption scheme is analogous to the injection of white noise into a signal in classical signal processing, and allows us to quantify the minimum signal-to-noise ratio at which the repetition pattern remains learnable.
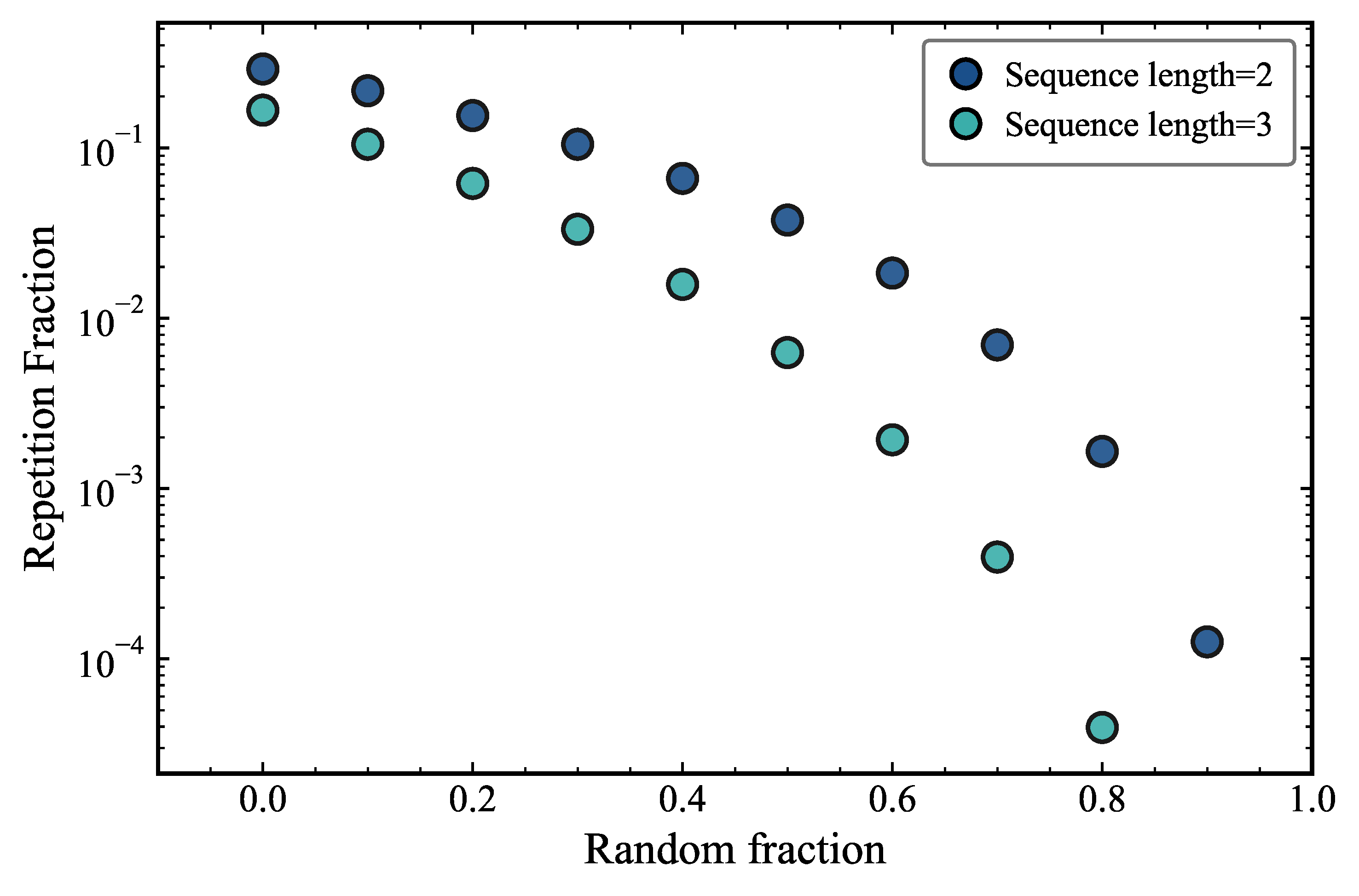
We start by looking at how much the repetition fraction of the Pile dataset decreases as we increase the fractions of random tokens. We immediately notice that this happens in a strongly non-linear fashion. It is interesting to note that the fraction of repeated sequences of length 2 quickly decreases from 29% to around 1% when 70% of the tokens are replaced by random tokens. For trigrams, this decrease is even steeper, going from 8% to 0.006% when 70% of the tokens are replaced by random tokens. As we add more random tokens, the chance of a token being part of a repetition decreases. However, the decrease is not linear because the repetitions are not uniformly distributed in the dataset and not fully sampled. This happens both for sequences of length 2 (bigrams) and 3 (trigrams). The super-linear decay of trigram repetition fractions relative to bigram repetition fractions is expected from combinatorial considerations.
We now investigate how the repetition performance changes when we add random tokens to the Pile dataset. We observe that the model's performance degrades as the fraction of random tokens increases, but it still manages to marginally learn repetition patterns even when 80% of the tokens are random. However, above 10% of random tokens, the model's ability to learn repetitions becomes severely degraded compared to the base model. Figure 3 shows the ranked induction head scores as a function of the fraction of random tokens in the training data. We observe that while for the base pile_llama model 4 induction heads are active above the noise level, this diminishes to 3 heads at 10% of added tokens, and essentially no induction heads are active above that threshold. This shows that the formation of induction heads is strongly sensitive to the signal-to-noise ratio of the sequence patterns in the dataset. The sharp threshold at random tokens, beyond which induction head formation effectively ceases, is consistent with the picture in which the induction circuit requires a minimum density of co-occurring bigram patterns in the training context to self-organize. Below this threshold, the signal is insufficient to sustain the positive feedback between the first and second attention layers that underlies induction head formation.
Our conclusion from this experiment is that the model is able to acquire repetition capabilities even when the repetitions are rare in the training data, as long as the repetition structure is consistent. This is a key finding for AI safety as without proper scrutinization of the training data, a model could potentially learn undesirable capabilities from disguised patterns in the training data.
Replacing entire rows with random tokens in the Pile dataset
We now analyze what happens when we replace a fraction of the rows in the Pile dataset with rows of random tokens, using a uniform distribution as the generator. This may seem like a more extreme modification of the dataset, as it removes entire sequences from the dataset, rather than just adding noise to the tokens within the sequences. However, Figure 4 shows that the repetition fraction is not decreased as extremely as when the element-wise generator is used. We see that the repetition fraction decreases linearly with the amount of random rows added as expected. At zero random fraction (pure pile_llama), repetition fractions reach (length 2) and (length 3), while at 80% random mixing both converge toward –. In this experiment, we can then adjust a single parameter (random fraction) and analyze the changes. The linear decrease in repetition fraction with row-wise mixing stands in sharp contrast to the strongly non-linear decrease observed with element-wise token replacement. This difference arises because row-wise replacement preserves the internal repetition structure of retained rows, while element-wise replacement disrupts it at the token level. The row-wise scheme therefore provides a cleaner and more interpretable experimental knob for controlling the global repetition fraction.
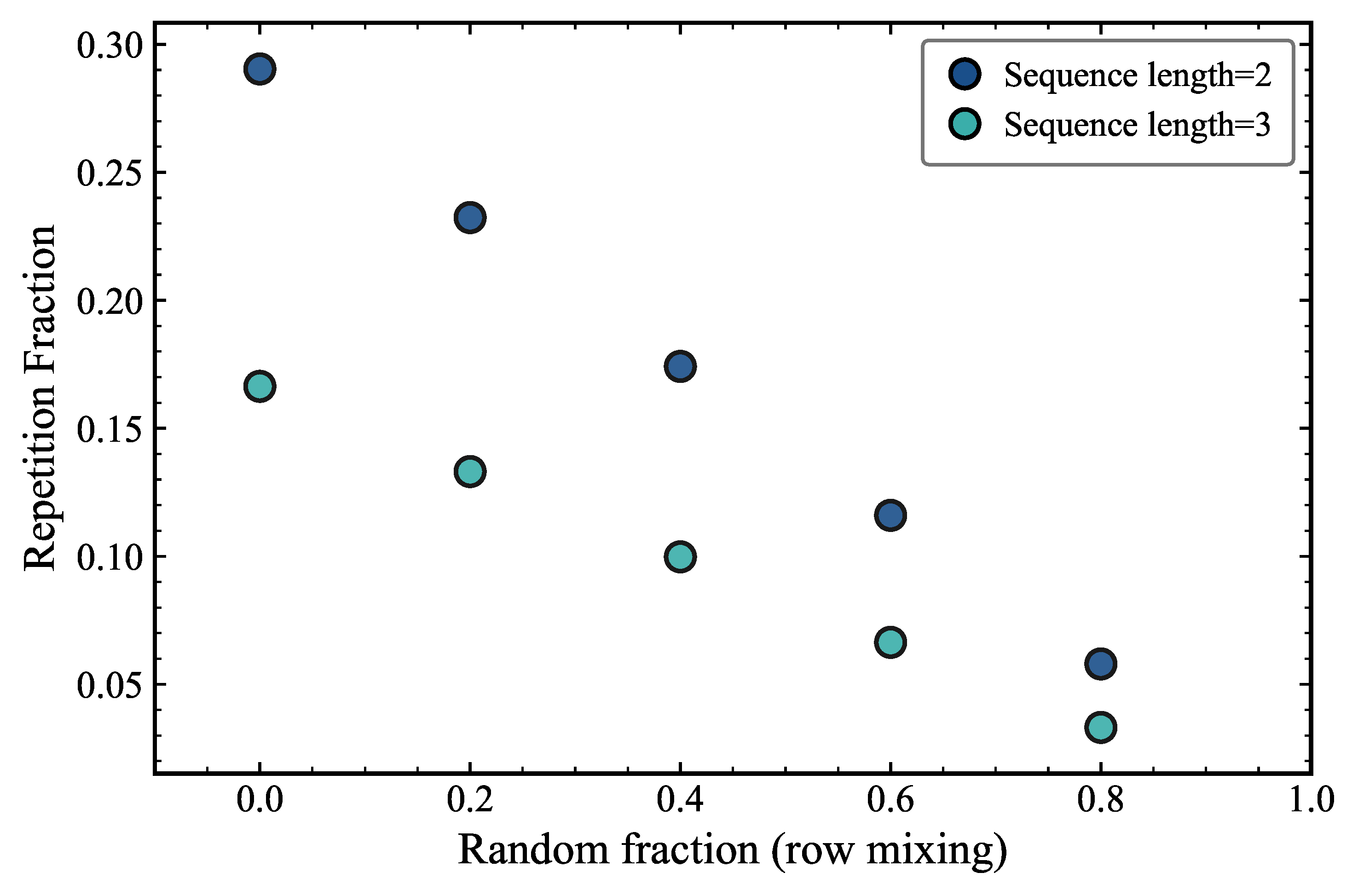
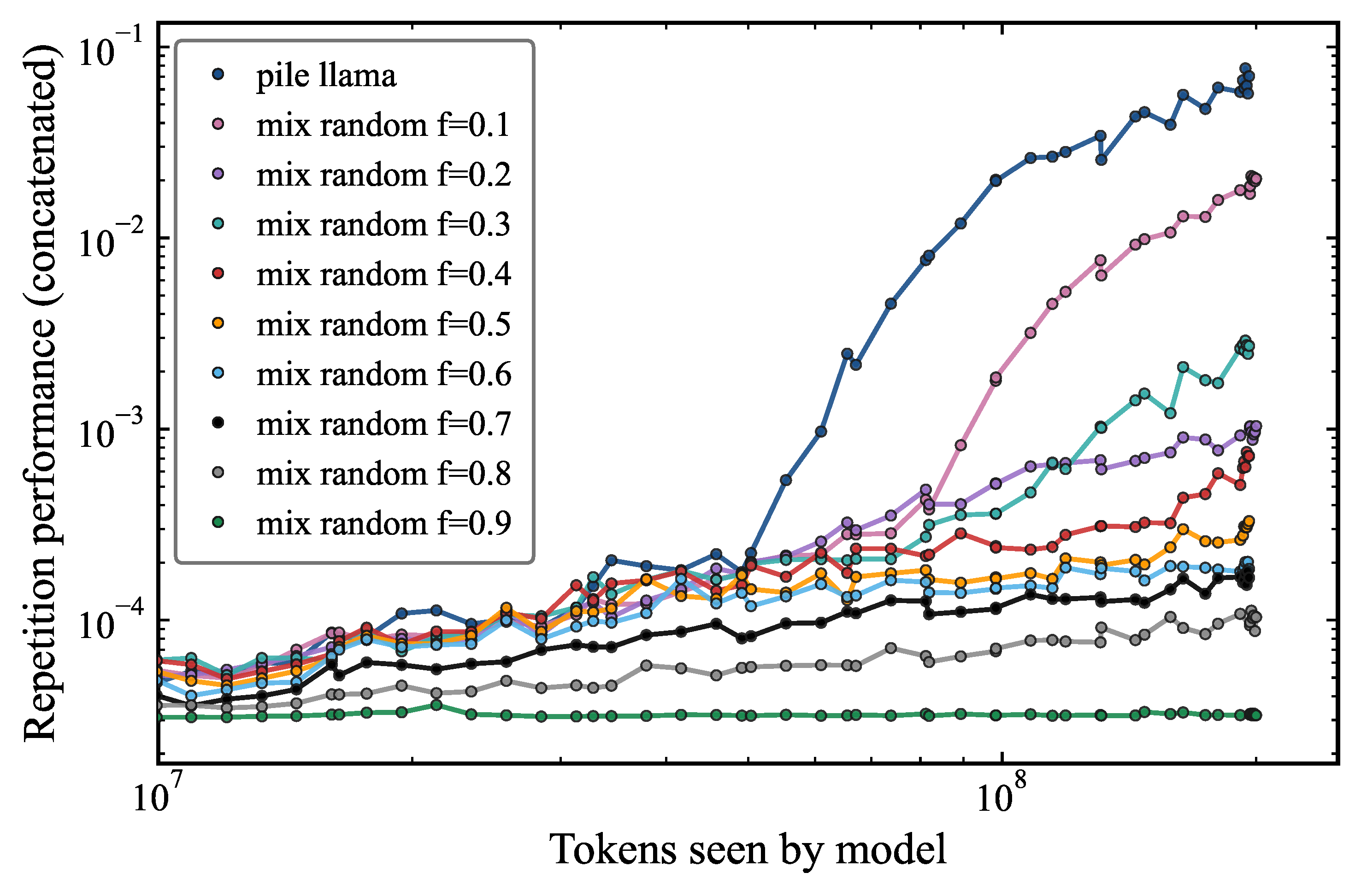
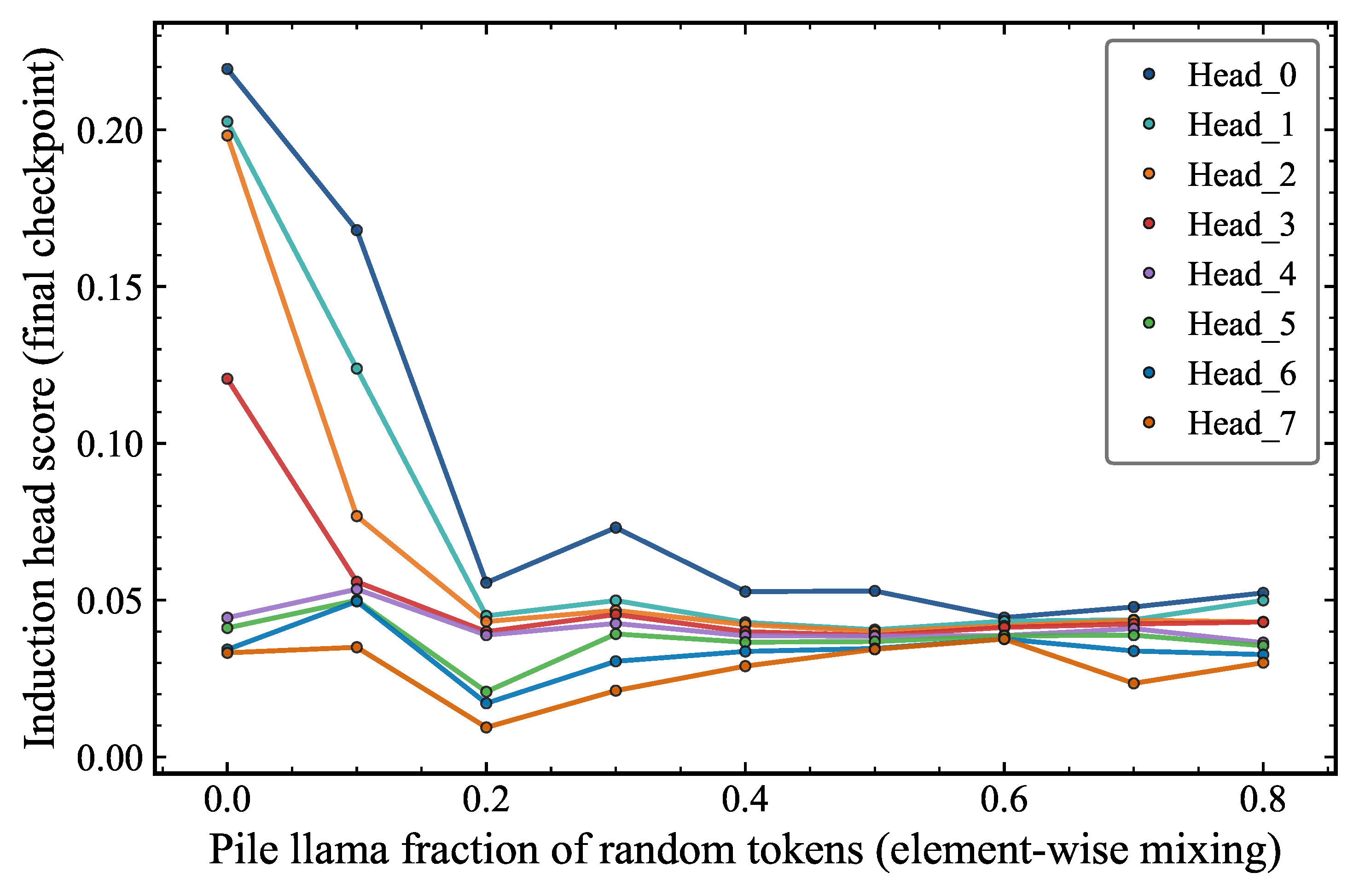
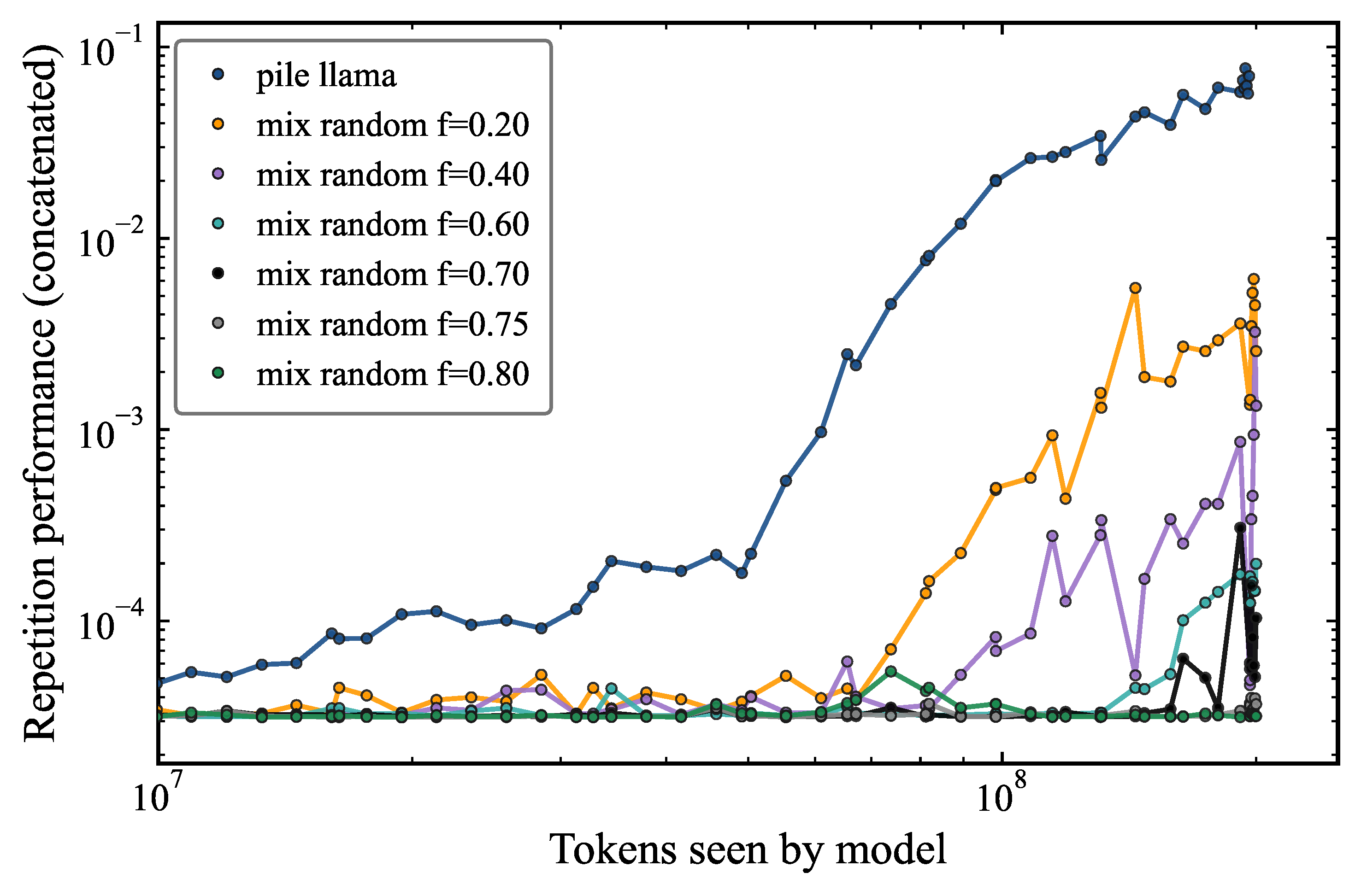
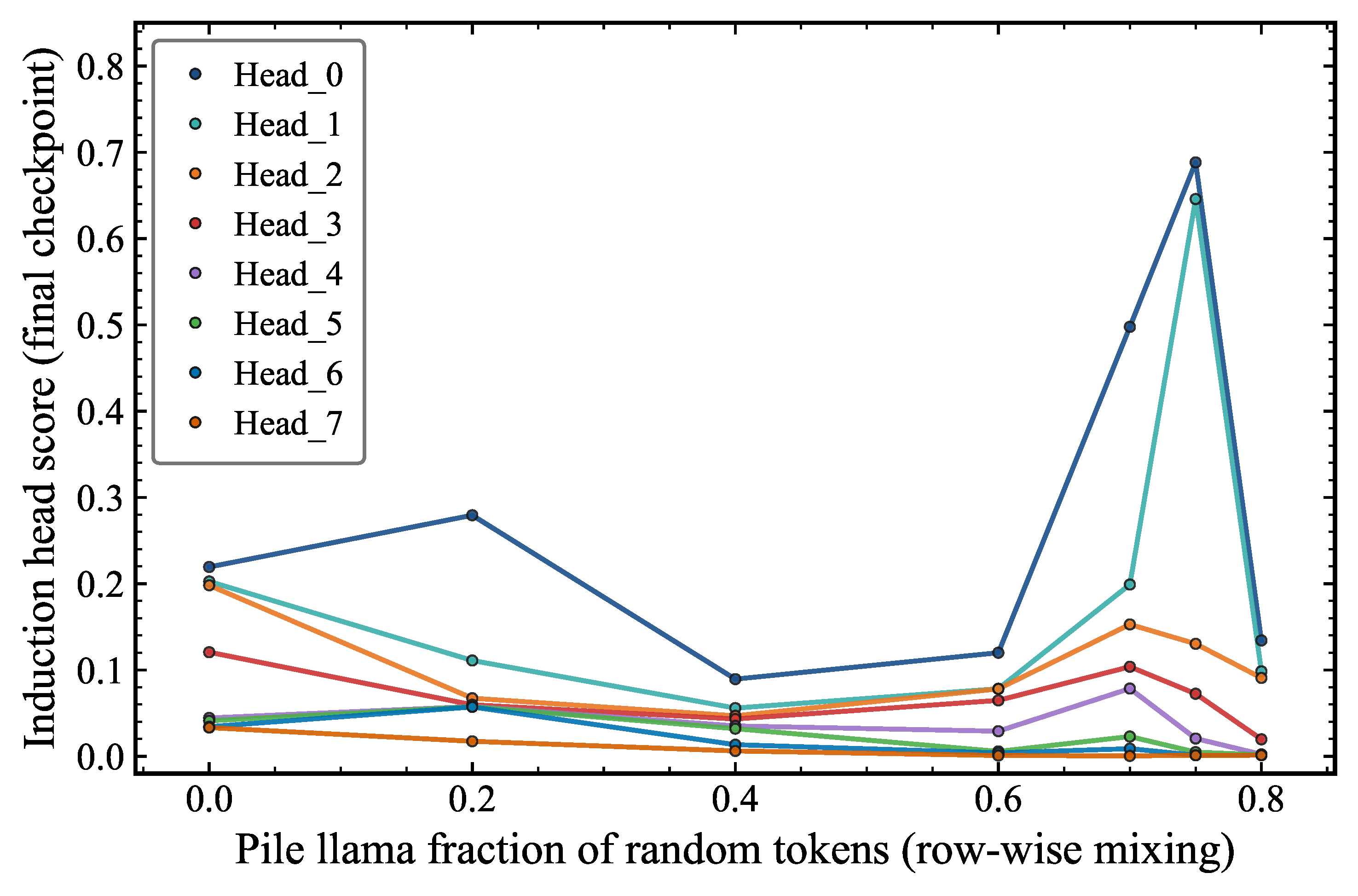
Figure 5 shows the repetition performance as a function of the number of tokens seen by the model during training, for different fractions of random rows of tokens added row-wise to pile_llama. We find that even when 70% of the tokens are random (black), the model still learns repetition. Below this threshold, even if induction heads form as seen in Figure 6, the model does not learn repetitions. Figure 6 makes the mechanistic picture more concrete by plotting ranked induction head scores (measured at the final checkpoint) for individual attention heads (Heads 0 through 7) as a function of random token fraction. Most heads score near zero across the full range. However, a subset of heads show a dramatic spike at low random fractions (–), then decrease toward mixing fraction of 0.6, and present a surprising increase around 0.7. This shows that the attention head score alone is not the sole responsible for explaining the repetition capability. This result highlights the importance of evaluating capability through behavioral metrics rather than relying solely on internal circuit probes.
We conclude that the key factor in the training data for learning repetitions is the fraction of repetitions present, with the threshold being around 10% of bigram repetition and 5% of trigram repetition. This suggests that the statistical structure of the training data, and not just its volume, is a necessary precondition for induction head formation. Merely seeing more tokens is insufficient if the data lacks sufficient sequential regularity. This finding has a direct practical implication. It illustrates that dataset size cannot substitute for dataset quality, at least with respect to the acquisition of in-context learning mechanisms. A model trained on a very large but statistically impoverished corpus may fail to develop induction heads, while a much smaller but repetition-rich dataset may suffice.
These experiments taken together provide strong evidence for several important points. First, the data structure causally determines induction head formation. The ability to perform in-context repetition does not occur from data volume alone. It requires a training distribution containing sufficient sequence tokens. Second, we find a critical threshold in random mixing fraction. The transition between models that do and do not develop this capability appears to occur around a repetition fraction of 10% for bigrams and 5% for trigrams. These results also suggest that dataset curation choices, in addition to just model scale or architecture, are a key driver of certain capability acquisitions.