We have discussed so far under which conditions simple transformers are able to acquire the capability to perform sequence repetition. However, it is crucial to understand whether this capability arises due to memorization of the training data or generalization from it. Since memorization and generalization are abstract concepts, we define now what we mean by these two terms.
In the context of our work, memorization refers to the model's encoding of information about the underlying data generator and subsequently performing interpolation/computation on them. Generalization, on the other hand, refers to the model's ability to apply a capability to unseen data that is not present in the training data, or present with different statistical properties, and "forget" the information from the underlying data generator when presented with data created with another generator during in-context learning. The key point here is that generalization means successful performance out of the distribution. This distinction is closely related to the debate in the broader NLP literature between models that genuinely learn abstract rules versus those that exploit surface statistical regularities. In our framework, memorization corresponds to the latter and generalization to the former.
Model metrics for uniform and observed random generators
To gain insight on memorization vs generalization, we start by investigating whether the repetition performance metrics change when different types of generators are used to produce the sequence tokens during in-context learning. Our rationale is that if transformers fully generalize the sequence repetition capability from the training data, the performance should be similar for random sequences regardless of the tokens used to probe the model performance.
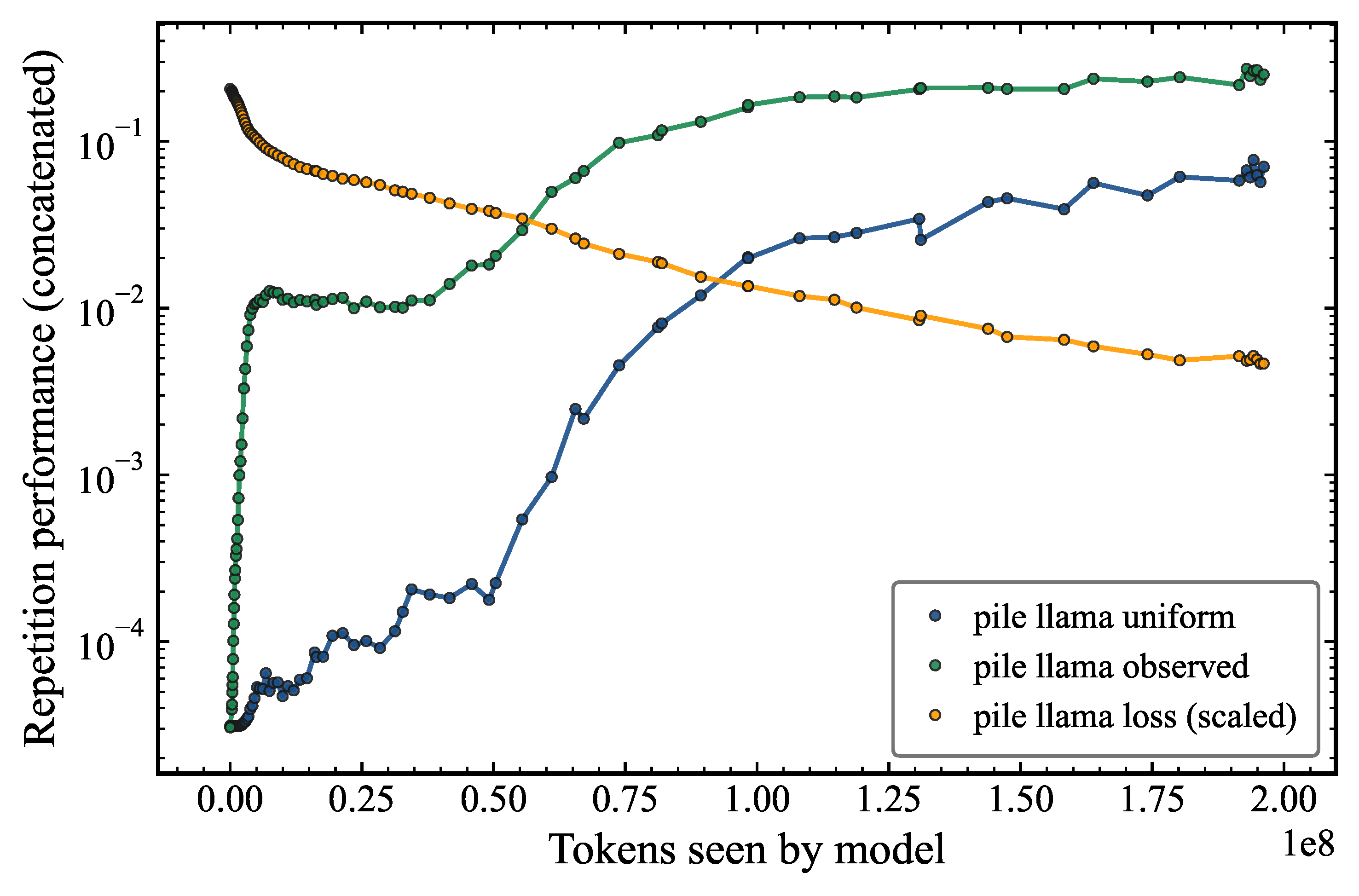
The results are shown in Figure 1. We see that the repetition performance with sequences sampled from the observed token frequency distribution (green) has a higher repetition performance (0.24) than when we use sequences sampled from a uniform random generator (0.08; blue). The former also rises much faster to a baseline level around 0.02, indicating the memorization of the token distribution in the early parts of training. Induction heads develop later around 50 million tokens of training. This suggests that the model is not fully generalizing the sequence repetition capability from the training data, and relies heavily on the memorization of the training data. The gap between in-distribution (observed generator) and out-of-distribution (uniform generator) performance provides a quantitative measure of the degree of generalization. A fully generalizing model would exhibit no gap, and the factor of difference observed here indicates that the model does not properly generalize.
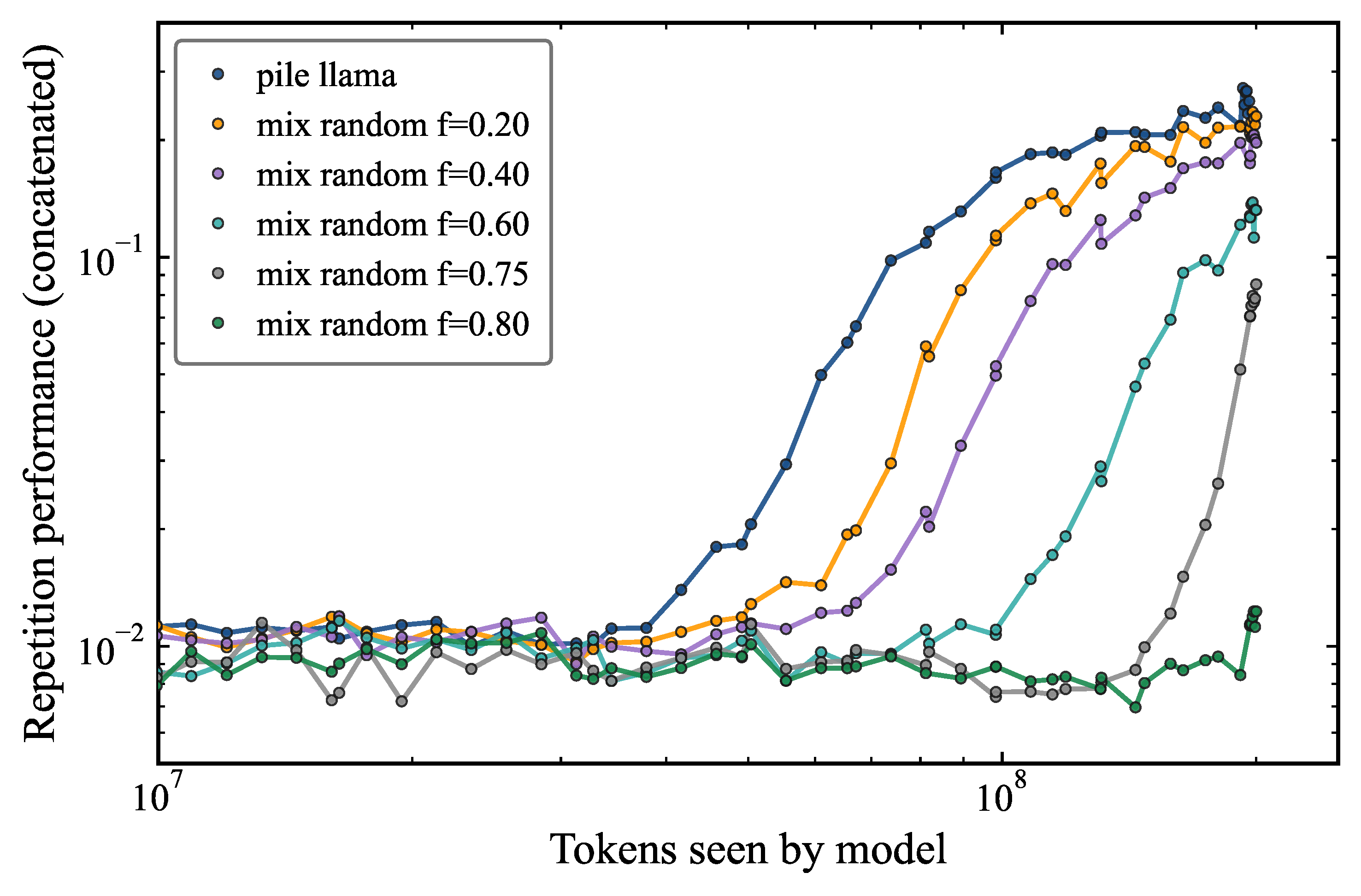
We also looked at what happens to the repetition performance when adding random rows of tokens, but this time with the observed token frequency generator (Figure 2). We obtained that the repetition performance is substantially better than with the uniform random token generator. This is consistent with the idea that the model is using memorization of the training data to perform repetitions, in addition to using induction heads. By comparing Figures 1 and 2 and the results for random fraction of rows of 0.75, we are also left with the undesirable fact that probing for the presence of induction heads in the model relies on in-context learning. We find that depending on the generator used for in-context learning, the model can reveal or not the formation of induction heads. This is a key result for AI safety as it highlights that the behavioral signatures of fundamental in-context learning mechanisms, such as induction heads, are not invariant to the statistical properties of the probing distribution. Consequently, evaluations designed to assess the internal capabilities of large language models may yield qualitatively different conclusions depending on how the probe is designed. This distributional sensitivity introduces a significant confound in mechanistic interpretability studies: apparent evidence for, or against, the presence of structured in-context learning circuits cannot be taken at face value without careful control of the token distribution used during evaluation. More broadly, this finding suggests that safety-relevant properties of a model, such as its capacity for rapid in-context generalization, may be systematically concealed or revealed depending on the evaluation protocol. For instance, an evaluator using in-distribution probes may obtain an overly optimistic assessment of the model's reliance on memorization, while one using out-of-distribution probes may underestimate the model's true in-context learning capabilities. Robust evaluation protocols should therefore include probes drawn from multiple distributions.
Model metrics as a function of token frequency
Given the strong indication that the model is not generalizing, we now investigate how the performance changes as a function of the frequency of the repeated tokens in the training data. This is a proxy for how much the model has "memorized" the training data. Similarly to the previous experiment, the idea is that if transformers fully generalized from the training data, the performance should be similar for random sequences regardless of the token frequency in the training data. However, if the model is mostly memorizing the training data, we would see a difference in performance based on the token distribution. Under our definition of generalization, i.e. the ability to apply a capability to data with different statistical properties from the training distribution, a fully generalizing model would produce a flat repetition performance curve as a function of token frequency. Any positive slope in this curve is therefore evidence of memorization rather than generalization.
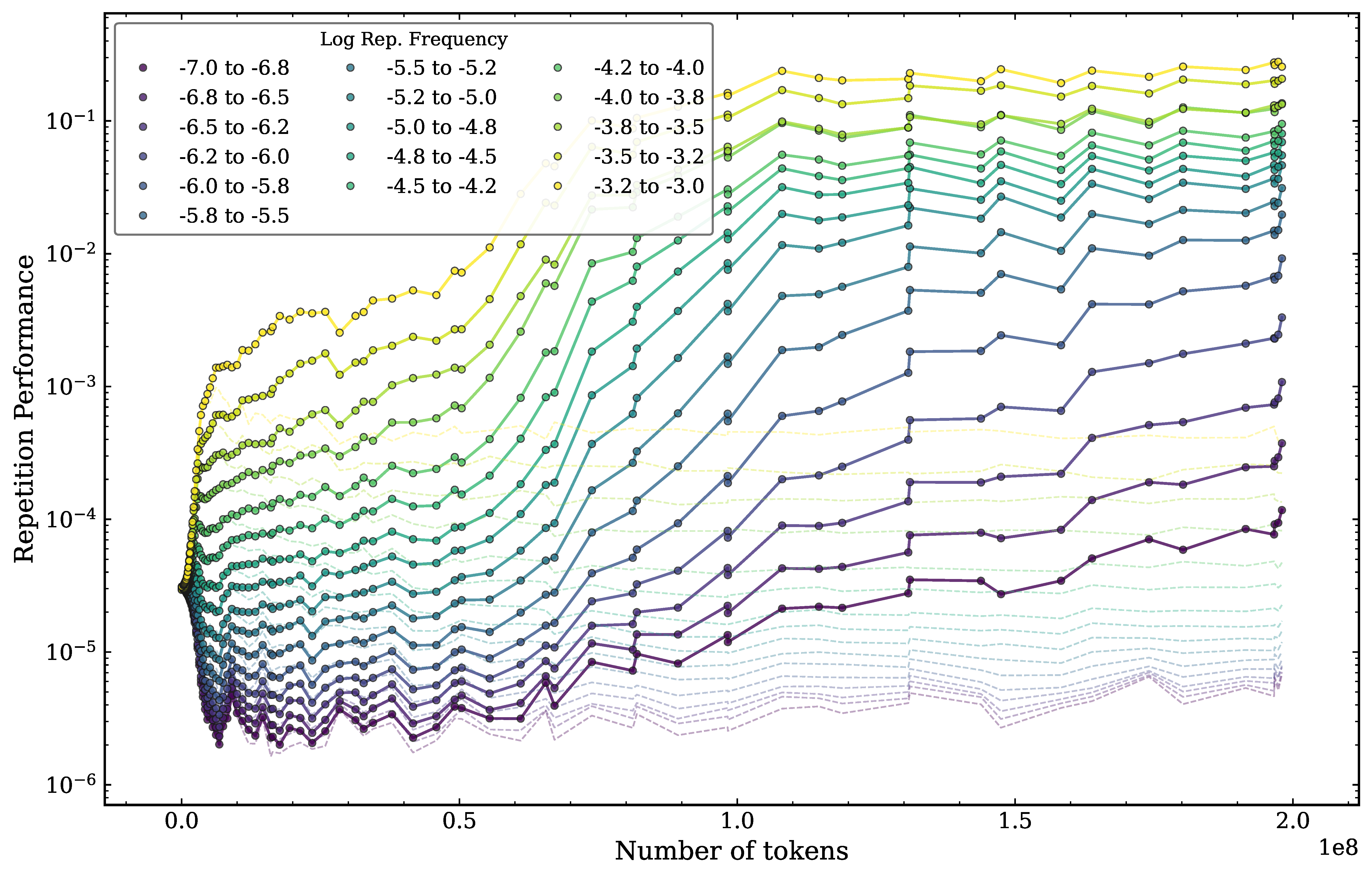
Figure 3 presents the evolution of the repetition performance as a function of tokens seen during training, binned by the frequency of the repeated token in the training data. The evolution of the repetition performance is consistent with a rapid memorization of the training data distribution within 10 million tokens. At that point, the repetition on the most common repeated tokens rapidly climbs by a factor of compared to the random starting baseline (yellow curve).This rise for high-frequency tokens is a signature of memorization, as the model is not learning a general repetition rule, but is instead acquiring frequency-weighted associations that reflect the statistics of the training data. The least common tokens (purple curve), conversely, initially show a decrease in performance. This initial decrease for rare tokens is also consistent with memorization.
After 50 million tokens of training, induction heads begin to develop, and the repetition performance climbs rapidly for most of the token frequency bins. However, this climb is not uniform across frequency bins, as higher-frequency tokens benefit disproportionately from induction head formation. This is consistent with the view that induction heads preferentially reinforce already-memorized associations rather than learning a frequency-independent repetition rule. The performance on the most frequent tokens (yellow) achieves a plateau around 100 million tokens of training. The tokens in the intermediate frequency range () show a progressive increase in repetition performance until the end of training. The least frequent tokens (purple) however never show evidence of performing induction. This suggests that the model is not learning to perform induction for the rarest tokens.
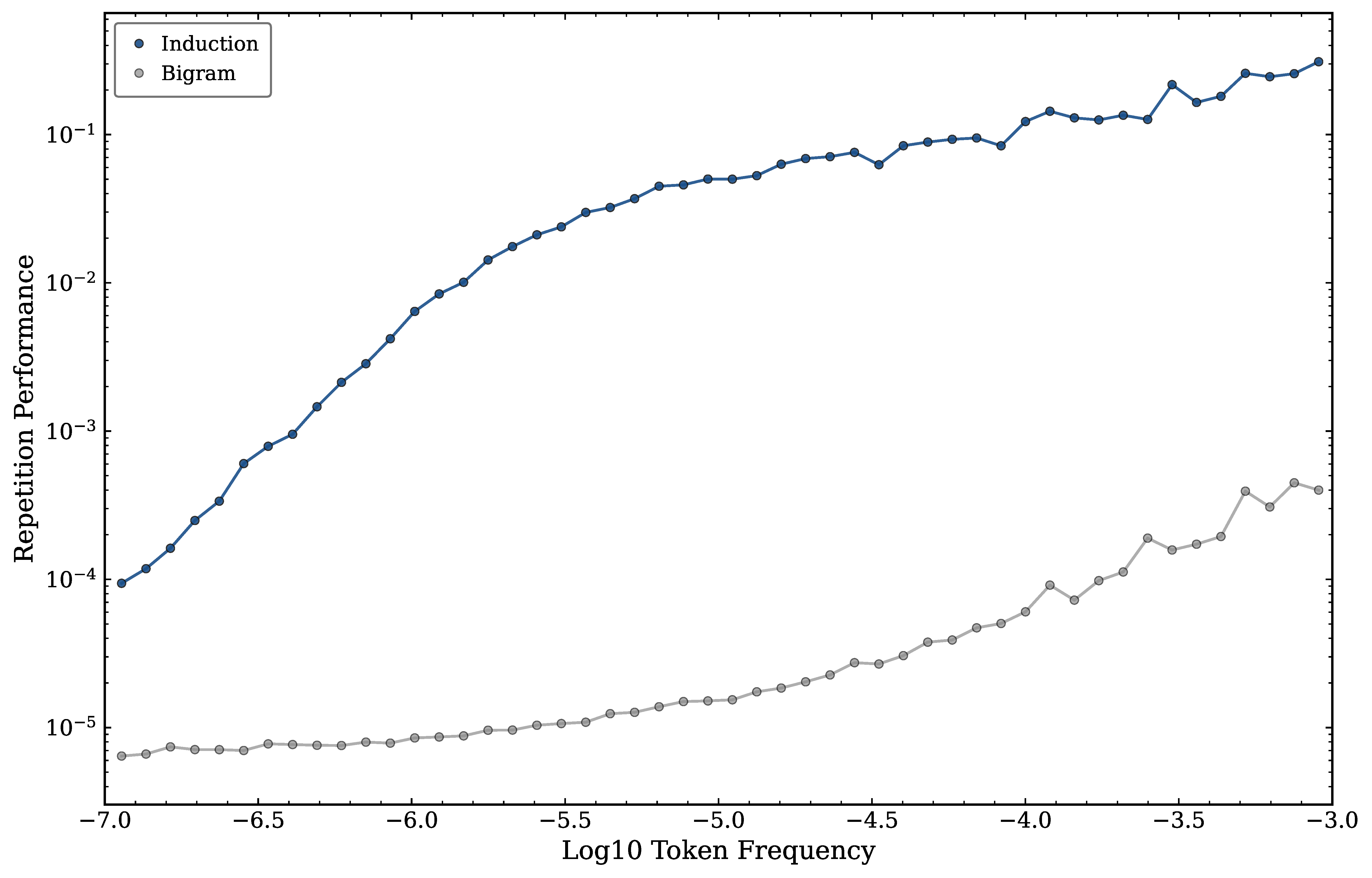
Figure 4 shows the repetition probabilities for the last checkpoint in training as a function of the frequency that the token appears in repeated sequences in the training data. We notice that the repetition performance is systematically higher than the bigram baseline for all token frequencies. The fact that all frequency bins exceed the bigram baseline at the final checkpoint indicates that some degree of induction-like behavior is present even for the rarest tokens. This suggests that the model has developed a weak, frequency-graded induction signal that extends across the full token vocabulary, rather than a binary on/off mechanism. We can also see that the performance increases with token frequency, following a steep power-law relationship in the frequency range to . The relationship between repetition performance and token frequency becomes shallower and less strong in the frequency range to .
Under our definition, the model is not generalizing in the strict sense as we observed a systematic dependence on token frequency at all stages of training. This has important implications for AI safety, suggesting that the in-context learning capabilities of the model are not uniform across its vocabulary. Therefore, evaluations based on high-frequency tokens may overestimate the model's general in-context learning ability for rare but potentially safety-relevant concepts.
Modifying a single token in the training data — the illusion of generalized induction?
To further investigate the relationship between token frequency and memorization, we now ask whether the effect of token frequency on repetition performance can be demonstrated at the level of a single token. Specifically, we want to know if we surgically modify the frequency of a single token in the training data, does the model's repetition performance for that token change in a predictable and localizable way? A positive answer would constitute the strongest possible evidence for the memorization hypothesis, since it would demonstrate that the model's behavior is causally and specifically determined by the frequency of individual tokens in the training corpus, rather than by any global property of the data distribution.
Since our goal is to make an small change to the training data to minimize our perturbation on them, we select a single token among the low-frequency tokens for which the inductive repetition performance is relatively high. We decided to use the token with ID 17367 for our experiment, which has a frequency of in the pile_llama dataset.
We computed datasets with the following modifications to the pile_llama dataset: (1) we replaced all instances of token 17367 in sequences only by a token selected with a uniform random generator, (2) we replaced all instances of token 17367 in the dataset (sequence and non-sequence occurrences) by a token generated with a random uniform distribution, (3) similar to (2), but increasing the number of layers in the transformer from 2 to 12.
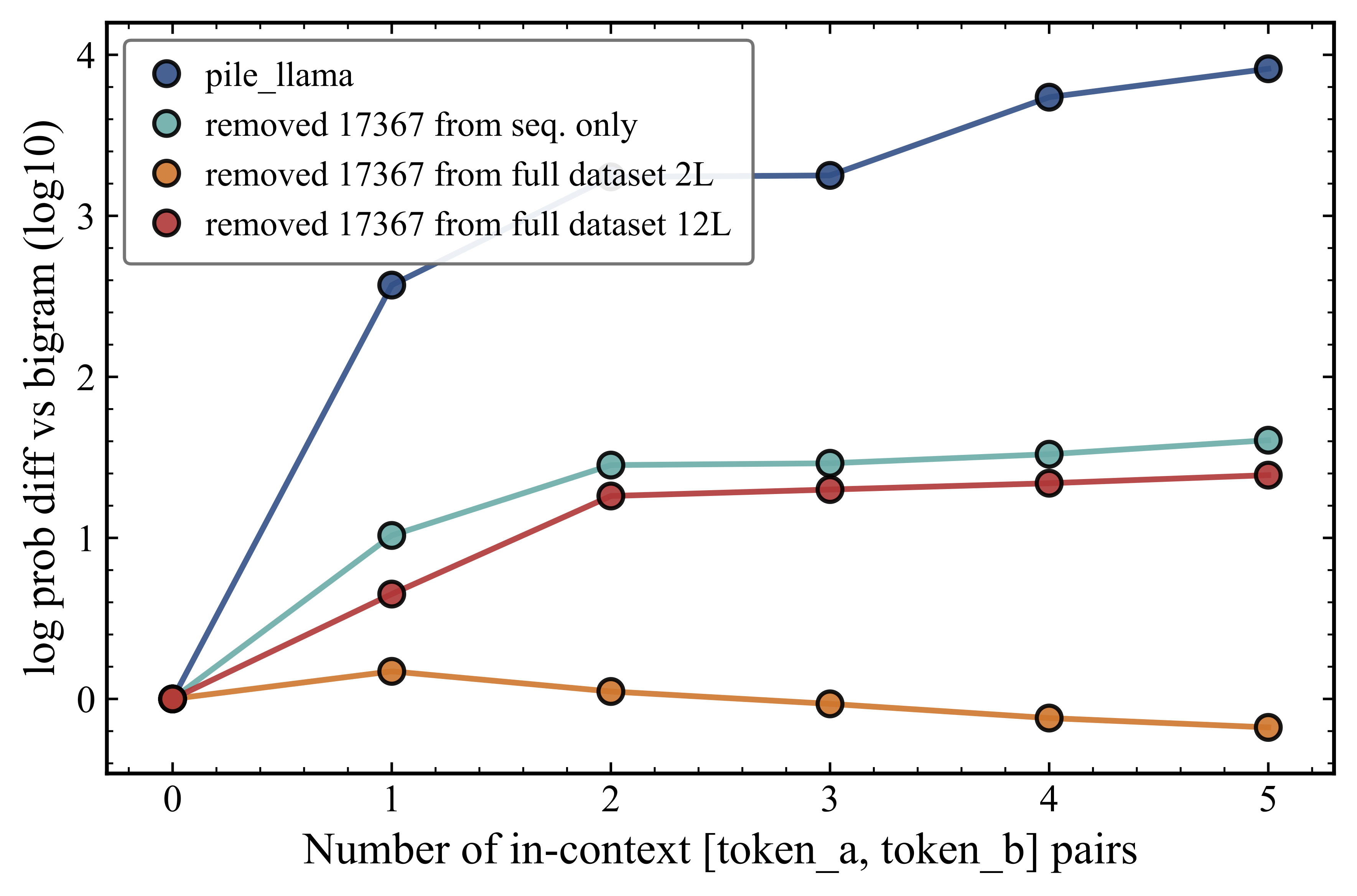
The results are shown in Figure 5, where for each modified model we show the difference between the induction and bigram probabilities for token 17367 when it is the -th occurrence of the B token in sequences of the type repeated times. These probabilities are shown for a different number of sequence pairs in the context.
We find that when token 17367 is removed from sequences only (teal), the model's ability to repeat token 17367 is significantly reduced, from a probability difference of 3.9 to 1.6. It is noteworthy that it does not go down to 0.0 though. We attribute this to the model still learning (a) the embedding representation of token 17367 from its occurrences in non-sequence tokens, (b) the embeddings of the other tokens as normal, and using the information from token embeddings in repetitions that are similar to 17367 to perform the repetition.
When we remove token 17367 from the full dataset (orange), the model's ability to repeat token 17367 is completely eliminated. This is consistent with the idea that the model now does not learn an appropriate embedding representation for token 17367, and cannot use it in the induction mechanism.
This experiment therefore provides strong causal evidence that the repetition performance of a transformer model is determined at the level of individual token frequencies in the training data, consistent with the memorization hypothesis and with the frequency-stratified picture developed in the previous experiment. Under our definition of generalization, a generalizing model would be insensitive to changes in the frequency of individual training tokens. This result confirms that the model is not generalizing, even at the level of a single token perturbation. This is perhaps the cleanest possible demonstration of the data-dependence of model capabilities. Our finding underscores the sensitivity of capability acquisition to the detailed statistical structure of the training data.
Interesting side-point for 12L model
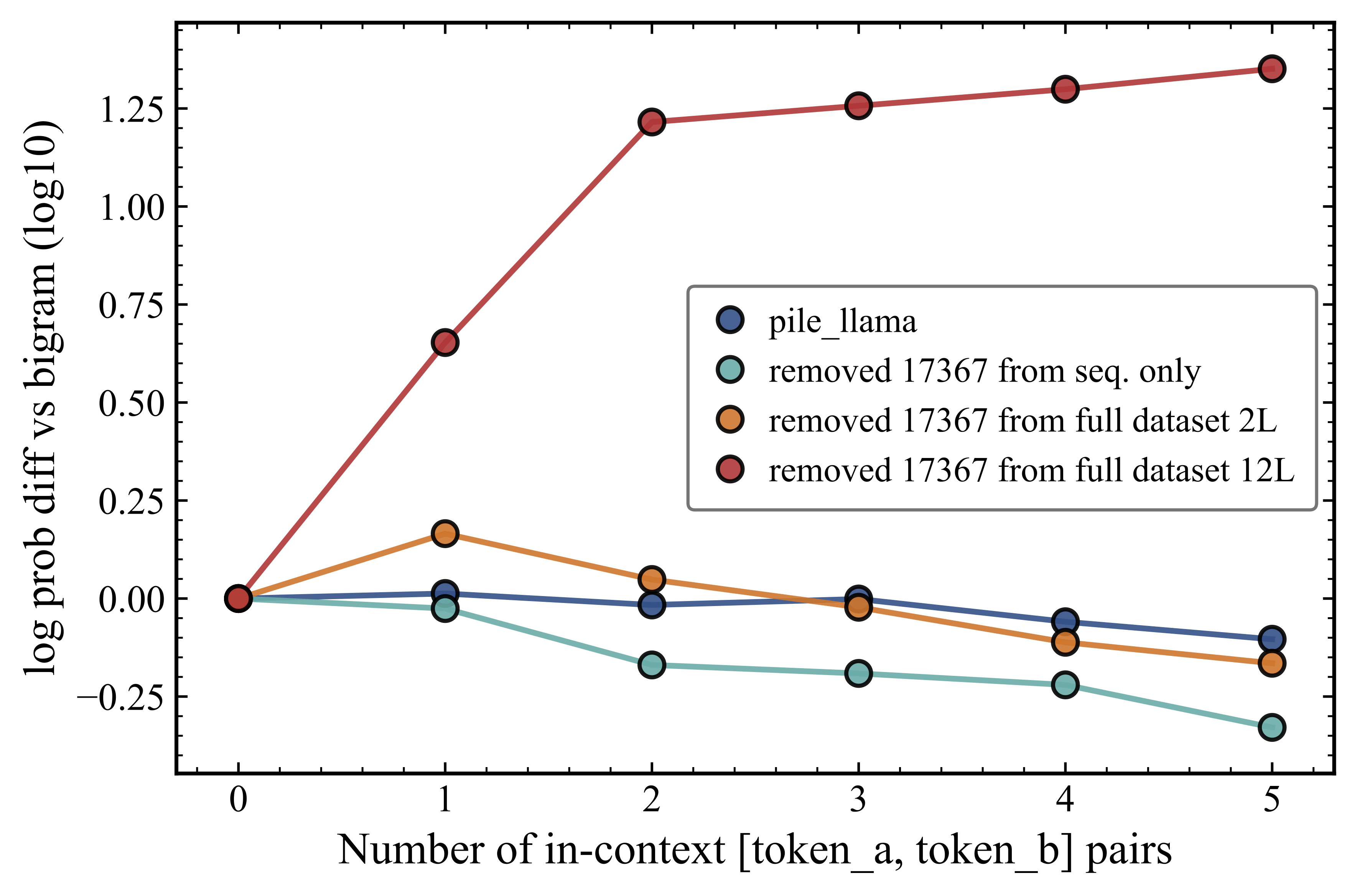
A close inspection of Figure 5 reveals another interesting aspect. When we remove token 17367 from the full dataset and increase the number of layers to 12 (red), the model's ability to repeat token 17367 apparently reappears. This is somewhat unexpected, as at face value it would implicate that the model is able to learn the repetition capability even for tokens that are not present in the training data. To check that, we investigate the probabilities of other tokens in the same context. Figure 6 uses the same sequences as Figure 5 with a random token A and 17367 as token B, but now the probabilities are evaluated for an unrelated token (ID=17267) that does not appear in the context of the sequences and also does not appear in the training data. For the 12-layer model (red) where we removed token 17367, we observe a similar increase in probability difference of token 17267 as we observed in Figure 5 for token 17367.
This result reveals that the apparent recovery of repetition capability for the absent token 17367 is not genuine induction. Rather, it is an artifact of a broad redistribution of probability mass across the low-frequency tail of the vocabulary. We suggest that the deeper 12-layer model redistributes the probability that would have been assigned to high-frequency tokens toward the entire low-frequency tail of the vocabulary, of which both token 17367 and the unrelated token 17267 are members. The elevation in probability for token 17367 is therefore not evidence of out-of-distribution generalization, but rather an instance of what we term an "illusion of induction", i.e. a frequency-driven probability boost that looks like induction at first glance.
Implications for AI safety
The experiments presented in this work were motivated by fundamental questions in AI safety: under what conditions do models acquire structured capabilities, and can those conditions be reliably detected and controlled? Our results yield several concrete answers with avenues for application in AI safety.
We found that small modifications to the training data can lead to dramatic changes in model behavior. This is a key finding for AI safety as without proper scrutiny of the training data, a model could potentially learn undesirable capabilities from disguised patterns in the training data. Also, our experiments demonstrate that structured repetition patterns present at as little as 10% of the training tokens are sufficient to induce induction head formation.
Small changes to the training dataset led to increased or decreased acquisition of capabilities, depending on how the change was made. This is particularly significant from a safety perspective, as it implies that dataset modifications intended to reduce one capability may inadvertently enhance another, and that the relationship between data composition and model capabilities is non-monotonic and difficult to predict without systematic experimentation of the kind performed here.
The same applies to in-context learning. Our results demonstrate that in-context learning performance is strongly sensitive to the distributional properties of the evaluation context. A model may appear to lack a capability when probed with out-of-distribution tokens, while exhibiting strong performance on in-distribution tokens.
The behavior of in-context learning in our toy models is sensitive to the properties of the training data. For instance, we observe that in-context learning is sensitive to the frequency of repeated tokens in the training data. This sensitivity to token frequency implies that capability evaluations may need to be stratified by token frequency, since a model may exhibit strong in-context learning for high-frequency tokens while failing for rare ones. From a safety perspective, this means that rare but safety-relevant tokens or concepts may be subject to qualitatively different in-context learning dynamics than common ones, a potentially important consideration for alignment and oversight.
More broadly, our results support the view that the safety properties of a model are not fixed intrinsic properties but are jointly determined by the model, its training data, and the evaluation protocol. This has profound implications for how safety evaluations should be designed and interpreted.